@Mitr-yuzr 在 [Mirai-NLP] GPT2-Chinese模型训练教程 中说:
@dream 这就是部署和接入部分了,可以肯定是可以的,你可以参考这篇帖子。
如果想接入chatlearning的话可能比较困难,你可以问一下chatlearning的开发者有没有提供相关接口。
关于部署,这一部分我也不确定我会不会做教程,毕竟本地推理的话估计比较废时间,而且gpt2模型只能做到文本生成和评估,在bot上应该没有应用场景。后续做对话模型的话参考大佬的文章也有教程。
@Mitr-yuzr 在 [Mirai-NLP] GPT2-Chinese模型训练教程 中说:
@dream 这就是部署和接入部分了,可以肯定是可以的,你可以参考这篇帖子。
如果想接入chatlearning的话可能比较困难,你可以问一下chatlearning的开发者有没有提供相关接口。
关于部署,这一部分我也不确定我会不会做教程,毕竟本地推理的话估计比较废时间,而且gpt2模型只能做到文本生成和评估,在bot上应该没有应用场景。后续做对话模型的话参考大佬的文章也有教程。
@cssxsh 若使用NLPHelper收集数据,emoji表情会自动被替换成空格。如果使用其他插件收集数据的话可以参考 使用Python对Json格式的数据进行二次处理为GPT2所需格式 这一部分,自己完成emoji的替换。
作为Mirai-NLP系列教程的第一章,本教程将会手把手教你从头开始训练一个基于GPT2-Chinese语言模型并进行文本生成。
本系列教程以及衍生插件均起源于 关于将QQ机器人与深度学习NLP结合的可能性 一帖,在这里对参与讨论和关注后续的各位表示感谢。没有你们的支持,我的寒假和国庆假期就不会这么充实。
本帖全部内容已经过作者验证,笔记本的内容也经过了封装,用户不需要接触到代码,只需输入参数即可进行训练和生成。
训练过程中如果出现问题可以回复或私聊,同时也非常欢迎各位在帖子下方分享自己的训练成果。
仅供学习用途,禁止用于任何违反法律法规和社区规定的行为,禁止用于商业行为。
请为你的QQBot安装用于收集数据的NLP插件:
或者如果你已经在使用Mirai Hibernate Plugin,则可以使用此插件:
相关插件的使用方法均在对应帖内有说明,本教程中不再介绍。
使用插件内置的导出数据有时无法满足我们想要的功能,这时可以导出Json格式的数据,并使用Python对数据进行二次处理为GPT2所需格式。
本教程中只介绍此方法的可行性,不详细讲解,下面给出一个例子,可用于针对 123456 的内容过滤。
import json
import ijson
if __name__ == "__main__":
with open('data.json', 'r', encoding='utf-8') as f:
objects = ijson.items(f, 'item')
new = []
while True:
try:
i = objects.__next__()
if i['size'] <= 100 and (i['sender']!=123456 or not "*龙门粗口*" in i['content']) :
new.append(i['content'])
except StopIteration as e:
print("数据过滤完成, 共" + str(len(new)) + "条符合要求的数据")
break
with open('train.json', 'w', encoding='utf-8') as f:
json.dump(new, f, ensure_ascii=False)
GPU,等待分配完成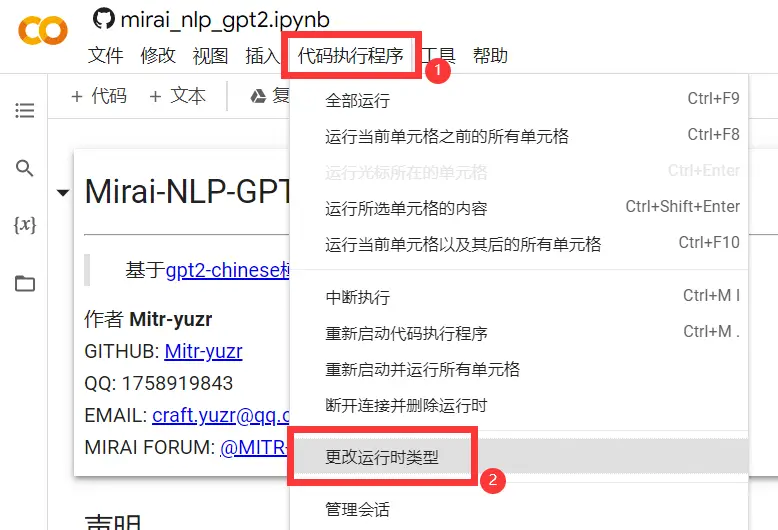
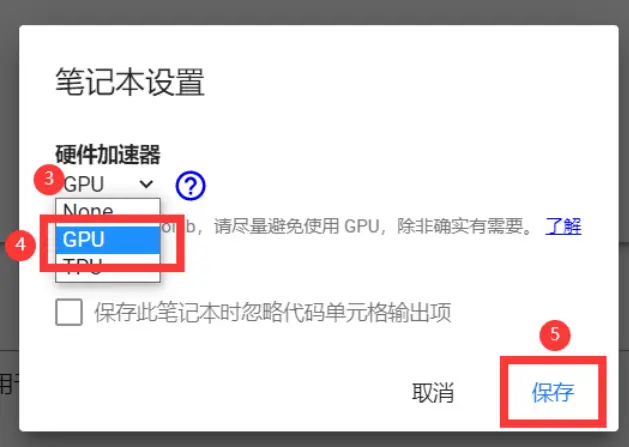



挂载Google Drive
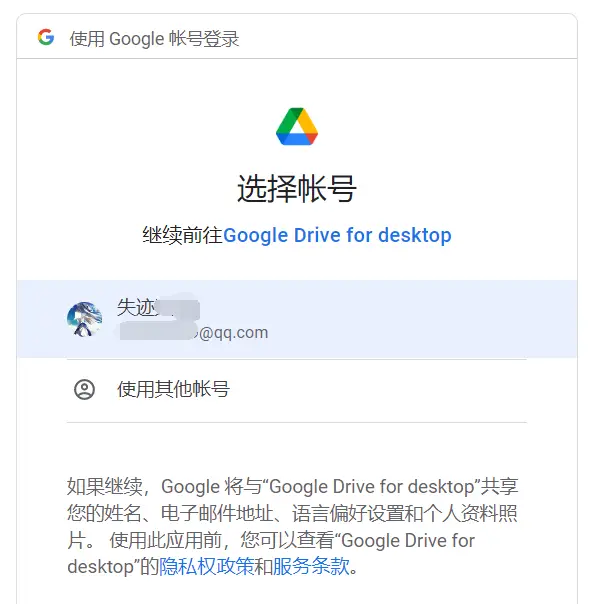
选择你的 Google 账号
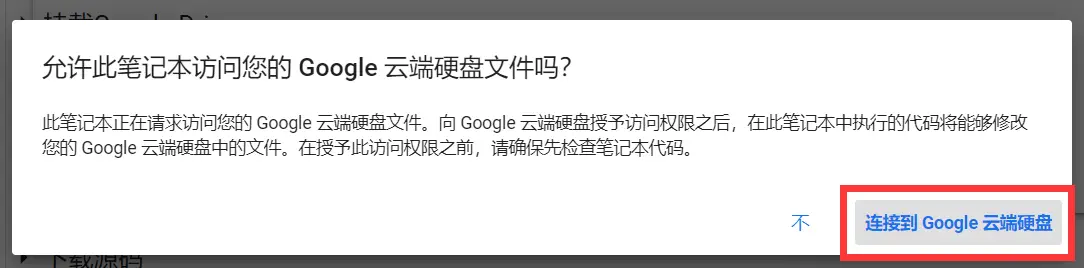
滑到最下方,允许
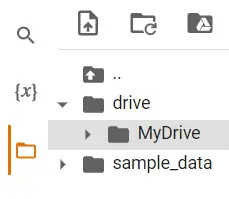
挂载成功后,可以看到左侧目录里已经出现了我们的GDrive文件夹
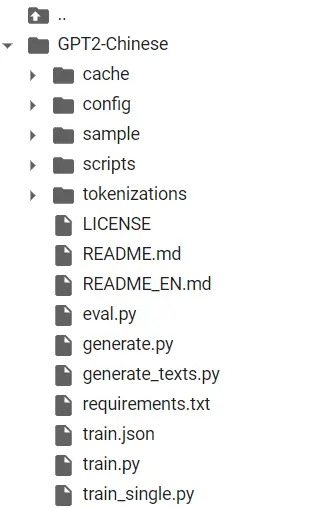
下载源代码
耗时可能比较久,我这里测试的是约五十秒。下载好后大约如下:
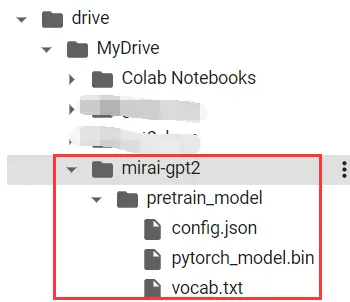
下载预训练模型
这里使用的是hhou435大佬提供的通用中文小模型。
你可以前往此处下载其他模型 (散文、诗词、对联、歌词、文言文等),并自行上传到drive/MyDrive/your_model_name/文件夹下。
若为二次训练 (即已经在GDrive中有训练过的模型),则无需运行此单元格。
下载好后可以看到在我们的GDrive挂载目录下出现了预训练模型(共三个文件)
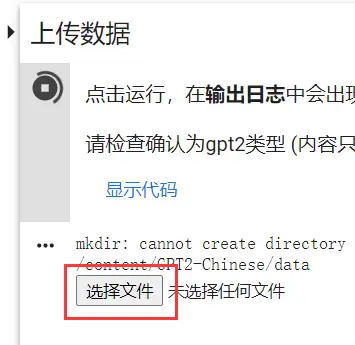
上传数据
运行后会在日志出现选择文件按钮,点击并选择导出的数据会自动上传到正确位置并重命名。
若文件较大则速度会比较慢,耐心等待即可。
至此,程序初始化已经完成。
依照笔记本内容仔细填写参数后,点击运行按钮进行训练。
关于参数的含义,笔记本中已经介绍的十分详细了。

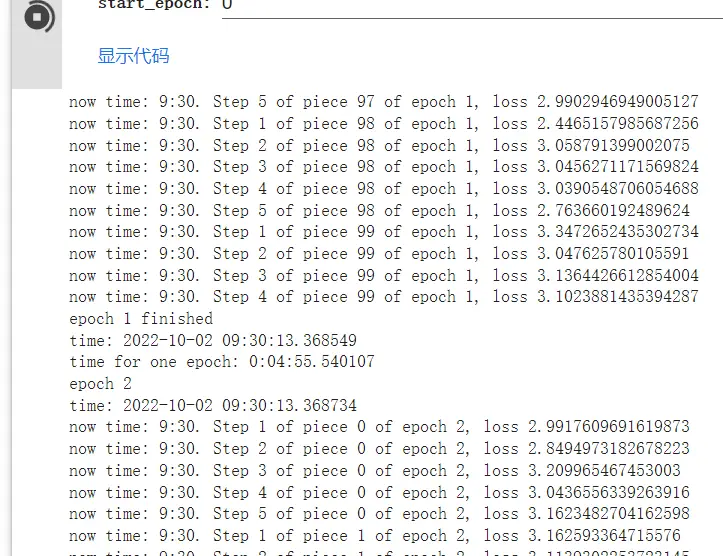
开始训练后会持续输出进度以及误差 (误差可能在0.5-0.1左右效果比较好,依数据量和内容也会发生变化)。
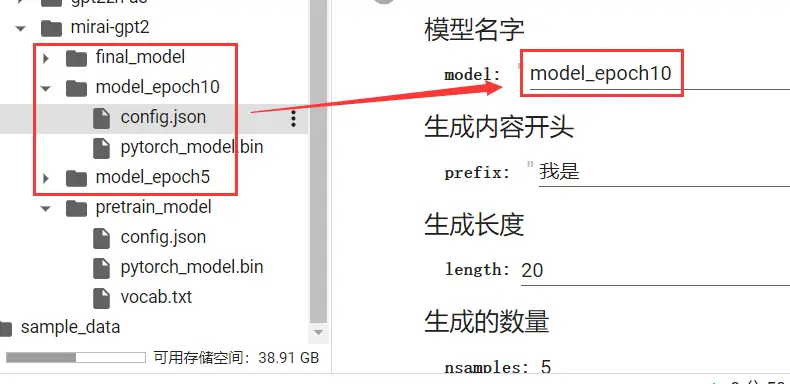
有时,我们训练完后可能觉得训练轮数不够或是被Colab强制停机了,亦或是增加了新数据,想接着训练先前的模型。
这时,我们需要修改以下参数。


之后点击运行按钮,就可以接着上次的进度继续训练了。
等待训练完成后,我们就可以进行文本生成了。
在下方生成参数中填写生成参数 (不能为空,修改后会自动运行,必须运行一次才可以进行生成)。
如果填写完后没有自动运行,可以自己手动运行一次。
参数填写完成并允许后,在下方可以看到两个代码块:
前者只会输出到日志,后者输出完成后会自动保存并下载。
两者效果一样,选择其中一个运行即可。

本教程至此已完成全部内容,由于部署对于一般用户而言太过困难且代价较高,因此本教程中不做介绍,可自行百度。
目前Mirai-NLP以及衍生插件只支持gpt2一种模型,未来预计还会支持更多其他模型,届时也会发布笔记本和教程,可以在Mitr-yuzr/Mirai-NLP-Notebook 仓库中查看。
由于数据集和预训练模型等问题,效果不理想是很正常的,但你已经踏入了机器学习领域的大门,并亲身体验了训练的全过程,这毫无疑问是一次难得的经验。
在如今的智能时代,NLP其实很近,并没有我们想的那么遥远。你打字时的自动联想,语音输入和识别、你的Siri、小爱,这些平日里见惯的内容,其实背后都有NLP辅助。
或许在未来的某一天,NLP真的发展到足以通过图灵测试的程度。你可能会想起在曾经启蒙的时代,你也曾有过一个属于自己的独一无二的AI,它可以水群,可以玩梗,会模仿你和你的朋友们说话。
内容大致就到这里了。如果教程有问题或是有困难可以回复或者私聊,也可以在github上提issue。
你也可以将你的训练成果分享到帖子下方,鼓励那些想试而迟迟未动手的用户去大胆尝试。
另外,在最后祝各位国庆节快乐。
@南栀沁寒 /NLPHelper exportBySQL "SELECT * FROM NLPH WHERE sender!=123456;" gpt2