[Mirai-NLP] GPT2-Chinese模型训练教程
-
Mirai-NLP > GPT2-Chinese
前言
作为Mirai-NLP系列教程的第一章,本教程将会手把手教你从头开始训练一个基于GPT2-Chinese语言模型并进行文本生成。
本系列教程以及衍生插件均起源于 关于将QQ机器人与深度学习NLP结合的可能性 一帖,在这里对参与讨论和关注后续的各位表示感谢。没有你们的支持,我的寒假和国庆假期就不会这么充实。
本帖全部内容已经过作者验证,笔记本的内容也经过了封装,用户不需要接触到代码,只需输入参数即可进行训练和生成。
训练过程中如果出现问题可以回复或私聊,同时也非常欢迎各位在帖子下方分享自己的训练成果。
声明
仅供学习用途,禁止用于任何违反法律法规和社区规定的行为,禁止用于商业行为。
需要
- 一台可以科学上网的电脑
- 可以使用Google Drive的Google账号
- 一个可以用于收集训练数据的QQBot
- 一点点动手能力
教程
数据准备
请为你的QQBot安装用于收集数据的NLP插件:
或者如果你已经在使用Mirai Hibernate Plugin,则可以使用此插件:
相关插件的使用方法均在对应帖内有说明,本教程中不再介绍。
使用Python对Json格式的数据进行二次处理为GPT2所需格式
使用插件内置的导出数据有时无法满足我们想要的功能,这时可以导出Json格式的数据,并使用Python对数据进行二次处理为GPT2所需格式。
本教程中只介绍此方法的可行性,不详细讲解,下面给出一个例子,可用于针对
123456的内容过滤。import json import ijson if __name__ == "__main__": with open('data.json', 'r', encoding='utf-8') as f: objects = ijson.items(f, 'item') new = [] while True: try: i = objects.__next__() if i['size'] <= 100 and (i['sender']!=123456 or not "*龙门粗口*" in i['content']) : new.append(i['content']) except StopIteration as e: print("数据过滤完成, 共" + str(len(new)) + "条符合要求的数据") break with open('train.json', 'w', encoding='utf-8') as f: json.dump(new, f, ensure_ascii=False)初始化笔记本
- 打开本项目的Colab笔记本
- 在右上角登录你的 Google 账号
- 首先点击右上角的连接,等待分配完成和初始化
- 在上方菜单栏中选择代码执行程序,在倒数第三项找到更改运行时类型,在硬件加速器中选择
GPU,等待分配完成
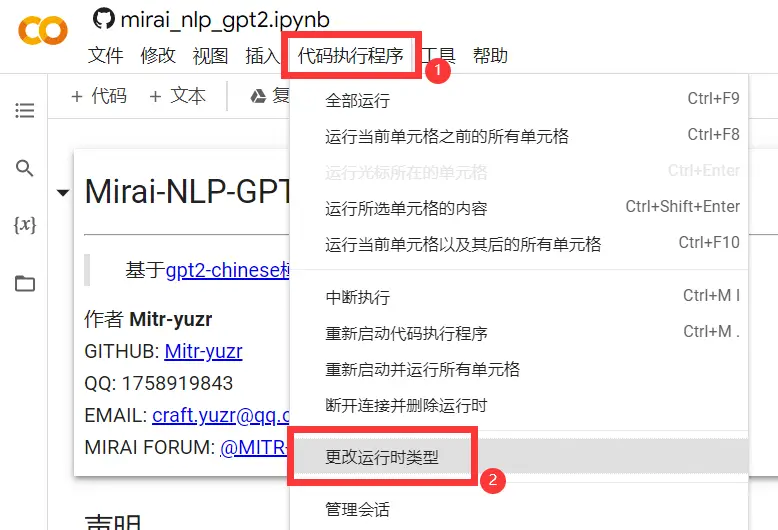
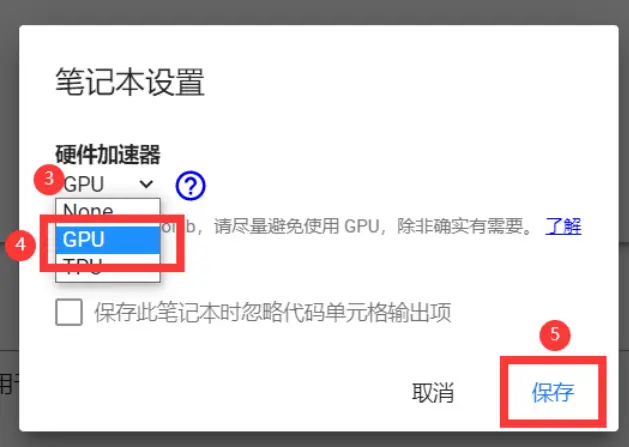
- 按照笔记本提示进行初始化、训练和生成

初始化源码、模型等
- 在全局变量单元格输入模型的名字,然后点击旁边的运行按钮

- 如果弹出安全提示则选择仍然运行

- 依次运行初始化单元格下的单元格
-
挂载Google Drive
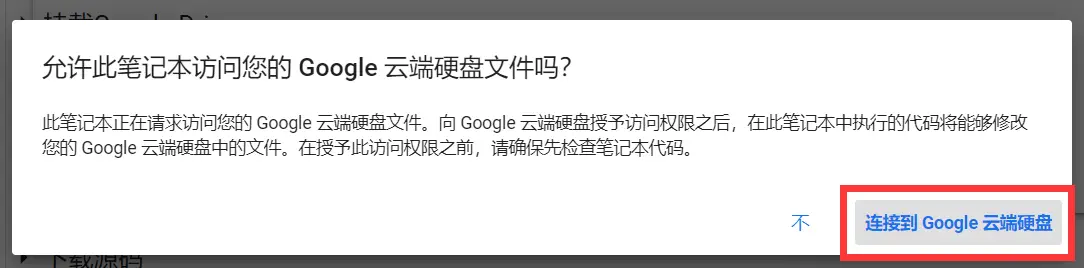
选择你的 Google 账号
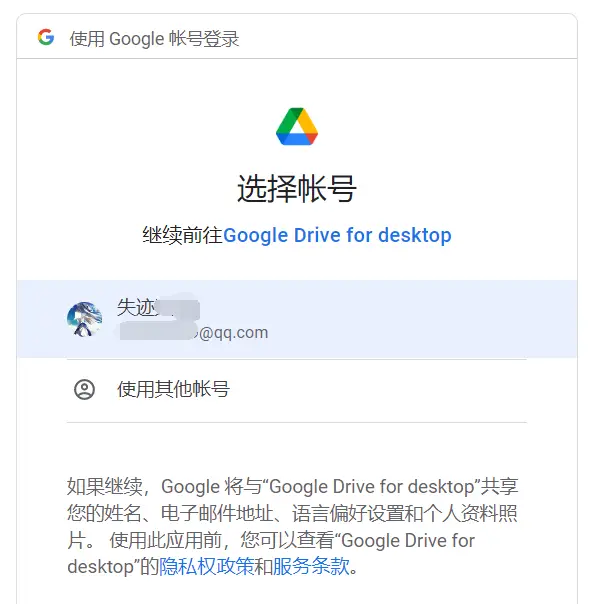
滑到最下方,允许
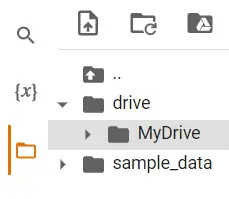
挂载成功后,可以看到左侧目录里已经出现了我们的GDrive文件夹
-
下载源代码
耗时可能比较久,我这里测试的是约五十秒。下载好后大约如下:
-
下载预训练模型
这里使用的是hhou435大佬提供的通用中文小模型。
你可以前往此处下载其他模型 (散文、诗词、对联、歌词、文言文等),并自行上传到drive/MyDrive/your_model_name/文件夹下。
若为二次训练 (即已经在GDrive中有训练过的模型),则无需运行此单元格。
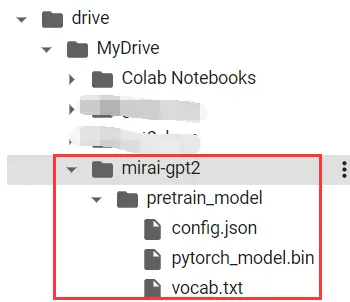
下载好后可以看到在我们的GDrive挂载目录下出现了预训练模型(共三个文件)
-
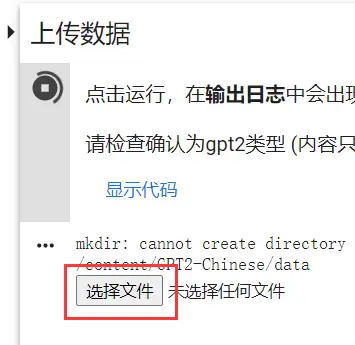
上传数据
运行后会在日志出现选择文件按钮,点击并选择导出的数据会自动上传到正确位置并重命名。
若文件较大则速度会比较慢,耐心等待即可。
-
至此,程序初始化已经完成。
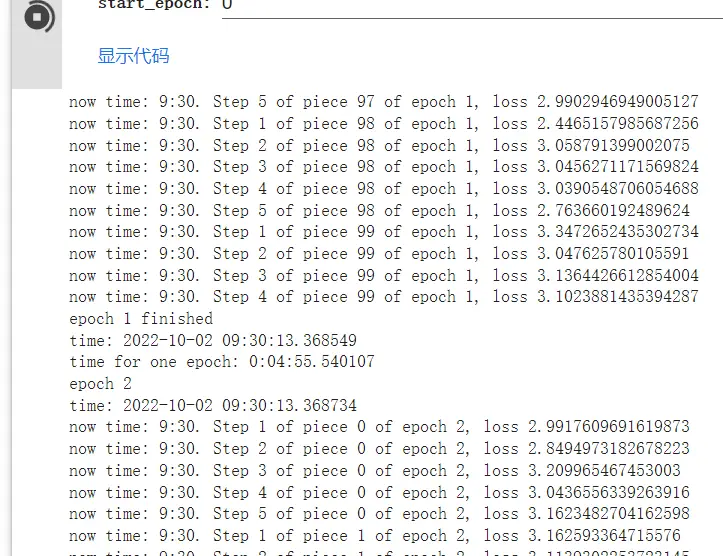
开始训练
依照笔记本内容仔细填写参数后,点击运行按钮进行训练。
关于参数的含义,笔记本中已经介绍的十分详细了。

开始训练后会持续输出进度以及误差 (误差可能在0.5-0.1左右效果比较好,依数据量和内容也会发生变化)。
如何进行二次训练
有时,我们训练完后可能觉得训练轮数不够或是被Colab强制停机了,亦或是增加了新数据,想接着训练先前的模型。
这时,我们需要修改以下参数。


之后点击运行按钮,就可以接着上次的进度继续训练了。
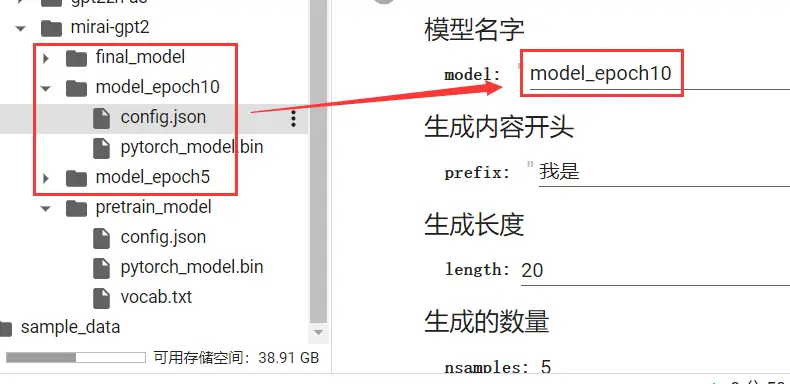
生成文本
等待训练完成后,我们就可以进行文本生成了。
在下方生成参数中填写生成参数 (不能为空,修改后会自动运行,必须运行一次才可以进行生成)。
如果填写完后没有自动运行,可以自己手动运行一次。
参数填写完成并允许后,在下方可以看到两个代码块:
- 直接生成
- 生成并保存至本地
前者只会输出到日志,后者输出完成后会自动保存并下载。
两者效果一样,选择其中一个运行即可。

结尾
本教程至此已完成全部内容,由于部署对于一般用户而言太过困难且代价较高,因此本教程中不做介绍,可自行百度。
目前Mirai-NLP以及衍生插件只支持gpt2一种模型,未来预计还会支持更多其他模型,届时也会发布笔记本和教程,可以在Mitr-yuzr/Mirai-NLP-Notebook 仓库中查看。
由于数据集和预训练模型等问题,效果不理想是很正常的,但你已经踏入了机器学习领域的大门,并亲身体验了训练的全过程,这毫无疑问是一次难得的经验。
在如今的智能时代,NLP其实很近,并没有我们想的那么遥远。你打字时的自动联想,语音输入和识别、你的Siri、小爱,这些平日里见惯的内容,其实背后都有NLP辅助。
或许在未来的某一天,NLP真的发展到足以通过图灵测试的程度。你可能会想起在曾经启蒙的时代,你也曾有过一个属于自己的独一无二的AI,它可以水群,可以玩梗,会模仿你和你的朋友们说话。
内容大致就到这里了。如果教程有问题或是有困难可以回复或者私聊,也可以在github上提issue。
你也可以将你的训练成果分享到帖子下方,鼓励那些想试而迟迟未动手的用户去大胆尝试。
另外,在最后祝各位国庆节快乐。
-
蛋疼的排版
-
Referenced by
 Mitr-yuzr
Mitr-yuzr -
Referenced by Mitr-yuzr
-
哦耶
-
可以直接用chatlearning使用吗
-
@dream 这你需要询问chatlearning的开发者是否提供了导出聊天数据的方式
-
我想知道训练大约需要多少时间。colab的免费版本只有k80显卡,速度实在太慢了。
-
@RainChan 我1080跑两千条数据24个epochs大概要跑三个小时,确实难绷
-
@Mitr-yuzr 不,我的意思是训练后的模型
-
-
@Mitr-yuzr 需要多少显存,等我有空可以拿我的3080ti跑一下,应该会很快
-
@RainChan 不记得了,我是上上个月跑的()
-
每一步都按部就班地完成了可是训练的时候只花了39秒就结束了好像么有训练上是什么情况 生成的文本也是默认的风格
2022-10-02 14:51:34.665015: W tensorflow/core/common_runtime/gpu/gpu_bfc_allocator.cc:39] Overriding allow_growth setting because the TF_FORCE_GPU_ALLOW_GROWTH environment variable is set. Original config value was 0.
args:
Namespace(batch_size=8, bpe_token=False, device='0,1,2,3', encoder_json='tokenizations/encoder.json', epochs=30, fp16=False, fp16_opt_level='O1', gradient_accumulation=1, log_step=1, lr=0.00015, max_grad_norm=1.0, min_length=128, model_config='/content/drive/MyDrive/mirai-gpt2/pretrain_model/config.json', num_pieces=31353, output_dir='/content/drive/MyDrive/mirai-gpt2/', pretrained_model='/content/drive/MyDrive/mirai-gpt2/pretrain_model', raw=True, raw_data_path='data/train.json', save_every=5, segment=False, start_epoch=0, stride=768, tokenized_data_path='data/tokenized/', tokenizer_path='/content/drive/MyDrive/mirai-gpt2/pretrain_model/vocab.txt', vocab_bpe='tokenizations/vocab.bpe', warmup_steps=2000, writer_dir='tensorboard_summary/')
config:
{
"activation_function": "gelu_new",
"architectures": [
"GPT2LMHeadModel"
],
"attn_pdrop": 0.1,
"embd_pdrop": 0.1,
"finetuning_task": null,
"gradient_checkpointing": false,
"initializer_range": 0.02,
"layer_norm_epsilon": 1e-05,
"model_type": "gpt2",
"n_ctx": 1024,
"n_embd": 768,
"n_head": 12,
"n_inner": null,
"n_layer": 6,
"n_positions": 1024,
"num_labels": 1,
"output_attentions": false,
"output_hidden_states": false,
"output_past": true,
"pruned_heads": {},
"resid_pdrop": 0.1,
"summary_activation": null,
"summary_first_dropout": 0.1,
"summary_proj_to_labels": true,
"summary_type": "cls_index",
"summary_use_proj": true,
"task_specific_params": {
"text-generation": {
"do_sample": true,
"max_length": 400
}
},
"tokenizer_class": "BertTokenizer",
"torchscript": false,
"use_bfloat16": false,
"vocab_size": 21128
}using device: cuda
building files
reading lines
100% 31353/31353 [00:01<00:00, 25351.73it/s]
finish
files built
number of parameters: 59541504
calculating total steps
100% 31353/31353 [00:00<00:00, 46655.81it/s]
total steps = 63
starting training
epoch 1
time: 2022-10-02 14:51:40.207784
epoch 1 finished
time: 2022-10-02 14:51:40.822857
time for one epoch: 0:00:00.615073
epoch 2
time: 2022-10-02 14:51:40.822894
epoch 2 finished
time: 2022-10-02 14:51:41.449992
time for one epoch: 0:00:00.627098
epoch 3
time: 2022-10-02 14:51:41.450048
epoch 3 finished
time: 2022-10-02 14:51:42.077769
time for one epoch: 0:00:00.627721
epoch 4
time: 2022-10-02 14:51:42.077812
epoch 4 finished
time: 2022-10-02 14:51:42.708398
time for one epoch: 0:00:00.630586
epoch 5
time: 2022-10-02 14:51:42.708441
saving model for epoch 5
epoch 5 finished
time: 2022-10-02 14:51:44.504427
time for one epoch: 0:00:01.795986
epoch 6
time: 2022-10-02 14:51:44.504479
epoch 6 finished
time: 2022-10-02 14:51:45.159980
time for one epoch: 0:00:00.655501
epoch 7
time: 2022-10-02 14:51:45.160022
epoch 7 finished
time: 2022-10-02 14:51:45.775230
time for one epoch: 0:00:00.615208
epoch 8
time: 2022-10-02 14:51:45.775269
epoch 8 finished
time: 2022-10-02 14:51:46.400834
time for one epoch: 0:00:00.625565
epoch 9
time: 2022-10-02 14:51:46.400874
epoch 9 finished
time: 2022-10-02 14:51:47.023521
time for one epoch: 0:00:00.622647
epoch 10
time: 2022-10-02 14:51:47.023573
saving model for epoch 10
epoch 10 finished
time: 2022-10-02 14:51:49.037504
time for one epoch: 0:00:02.013931
epoch 11
time: 2022-10-02 14:51:49.038147
epoch 11 finished
time: 2022-10-02 14:51:49.708357
time for one epoch: 0:00:00.670210
epoch 12
time: 2022-10-02 14:51:49.708414
epoch 12 finished
time: 2022-10-02 14:51:50.342309
time for one epoch: 0:00:00.633895
epoch 13
time: 2022-10-02 14:51:50.342346
epoch 13 finished
time: 2022-10-02 14:51:51.120483
time for one epoch: 0:00:00.778137
epoch 14
time: 2022-10-02 14:51:51.120527
epoch 14 finished
time: 2022-10-02 14:51:51.818518
time for one epoch: 0:00:00.697991
epoch 15
time: 2022-10-02 14:51:51.818555
saving model for epoch 15
epoch 15 finished
time: 2022-10-02 14:51:53.887909
time for one epoch: 0:00:02.069354
epoch 16
time: 2022-10-02 14:51:53.887966
epoch 16 finished
time: 2022-10-02 14:51:54.638956
time for one epoch: 0:00:00.750990
epoch 17
time: 2022-10-02 14:51:54.638997
epoch 17 finished
time: 2022-10-02 14:51:55.352443
time for one epoch: 0:00:00.713446
epoch 18
time: 2022-10-02 14:51:55.352490
epoch 18 finished
time: 2022-10-02 14:51:56.041411
time for one epoch: 0:00:00.688921
epoch 19
time: 2022-10-02 14:51:56.041461
epoch 19 finished
time: 2022-10-02 14:51:56.683434
time for one epoch: 0:00:00.641973
epoch 20
time: 2022-10-02 14:51:56.683474
saving model for epoch 20
epoch 20 finished
time: 2022-10-02 14:51:58.132586
time for one epoch: 0:00:01.449112
epoch 21
time: 2022-10-02 14:51:58.132646
epoch 21 finished
time: 2022-10-02 14:51:58.956908
time for one epoch: 0:00:00.824262
epoch 22
time: 2022-10-02 14:51:58.956947
epoch 22 finished
time: 2022-10-02 14:51:59.660956
time for one epoch: 0:00:00.704009
epoch 23
time: 2022-10-02 14:51:59.660999
epoch 23 finished
time: 2022-10-02 14:52:00.359305
time for one epoch: 0:00:00.698306
epoch 24
time: 2022-10-02 14:52:00.359344
epoch 24 finished
time: 2022-10-02 14:52:01.096733
time for one epoch: 0:00:00.737389
epoch 25
time: 2022-10-02 14:52:01.096784
saving model for epoch 25
epoch 25 finished
time: 2022-10-02 14:52:02.663749
time for one epoch: 0:00:01.566965
epoch 26
time: 2022-10-02 14:52:02.663813
epoch 26 finished
time: 2022-10-02 14:52:03.444945
time for one epoch: 0:00:00.781132
epoch 27
time: 2022-10-02 14:52:03.444996
epoch 27 finished
time: 2022-10-02 14:52:04.191383
time for one epoch: 0:00:00.746387
epoch 28
time: 2022-10-02 14:52:04.191432
epoch 28 finished
time: 2022-10-02 14:52:04.841133
time for one epoch: 0:00:00.649701
epoch 29
time: 2022-10-02 14:52:04.841188
epoch 29 finished
time: 2022-10-02 14:52:05.454232
time for one epoch: 0:00:00.613044
epoch 30
time: 2022-10-02 14:52:05.454272
saving model for epoch 30
epoch 30 finished
time: 2022-10-02 14:52:06.953251
time for one epoch: 0:00:01.498979
training finished -
https://github.com/yuanhong18/emojiswitch
这个工具可以替换emoji字符,希望整合
-
开始炼丹.jpg
-
此回复已被删除! -
@南栀沁寒 数据长度限制忘记调了(
现在修改了一下,再试试? -
@Samarium150 之前出了一点小问题,数据被模型自带的长度过滤给过滤掉了,可能需要重新跑一下()
-
@RainChan 之前出了一点小问题,数据被模型自带的长度过滤给过滤掉了,可能需要重新跑一下()
-
@cssxsh 若使用NLPHelper收集数据,emoji表情会自动被替换成空格。如果使用其他插件收集数据的话可以参考 使用Python对Json格式的数据进行二次处理为GPT2所需格式 这一部分,自己完成emoji的替换。
-
@Mitr-yuzr ok了!期待后续 不知道后面是打算怎样将训练好的模型接入到bot上呢 触发条件是什么(@?还是说概率回复的那种)