Dituon 发布的帖子
-
RE: 关于Mirai的一些小问题发布在 使用交流
欢迎回到未来
- 作为Bot框架来说能用,作为登陆协议完全不能用了,所以有了qsign签名服务。
- 目前主流的方案为使用 Overflow 对接 Napcat 等 NTQQ 客户端实现稳定登录。

-
在QQ中实现非等宽字体排版发布在 摸鱼区
其实一年前就写好了,今天整理资料时发现了这篇草稿,简单完善一下就发了
引言
假设要在纯文本消息中实现表格排版
例如:
│ id │ name │ │ dog │ 小狗 │ │ cat │ 哈基米 │于是出现了经典的 「错位地狱」:单纯在字符上进行对齐 (例如编程语言中的 pad string 方法),会导致全角字符也被偏移一个空格的距离。
解决方法当然也很简单,每个全角字符在等宽字体下约等于2个半角空格,只要将全角字符进行额外偏移就好。│ id │ name │ │ dog │ 小狗 │ │ cat │ 哈基米 │这种方法在等宽字体下近乎完美,但日常使用的几乎都是非等宽字体,当然也包括各种社交媒体。
│ id │ name │
│ dog │ 小狗 │
│ cat │ 哈基米 │于是就有了这篇文章。
视觉宽度
在非等宽字体的环境中,字符的 「视觉宽度」 不再是一个可以被简单计算的常数。
比如**「i」和「m」**这两个半角字母,在同一行里甚至能差出半个汉字的距离。于是,想在聊天栏或其它非等宽环境中整齐地输出一张表,就成了一场灾难。
不同系统、不同字体、甚至不同版本的 QQ 都会导致完全不同的视觉结果。
只能回到最古老、最笨但最有效的办法——以视觉为准,用算法补偿。
测量
以大家常用的 NTQQ 为准,chromium 内核的默认字体为
Arial (sans-serif), 我注入了 chromium 进程,用脚本测量了每个 ascii 字体的像素宽度,得出以下表格:{ " ": 4.1500, "!": 4.3750, "\"": 6.1000, "#": 8.9375, "$": 8.2125, "%": 12.4625, "&": 12.1875, "'": 3.6000, "(": 4.6875, ")": 4.6875, "*": 6.3750, "+": 10.3875, ",": 3.3750, "-": 6.0625, ".": 3.3750, "/": 5.9875, "0": 8.2125, "1": 8.2125, "2": 8.2125, "3": 8.2125, "4": 8.2125, "5": 8.2125, "6": 8.2125, "7": 8.2125, "8": 8.2125, "9": 8.2125, ":": 3.3750, ";": 3.3750, "<": 10.3875, "=": 10.3875, ">": 10.3875, "?": 6.7625, "@": 14.4375, "A": 9.8625, "B": 8.7875, "C": 9.3750, "D": 10.6750, "E": 7.7000, "F": 7.4375, "G": 10.4125, "H": 10.8375, "I": 4.1250, "J": 5.5500, "K": 8.8875, "L": 7.1875, "M": 13.6875, "N": 11.3875, "O": 11.4125, "P": 8.5750, "Q": 11.4125, "R": 9.1500, "S": 8.0875, "T": 8.0375, "U": 10.4625, "V": 9.4750, "W": 14.2500, "X": 9.0375, "Y": 8.4500, "Z": 8.6875, "[": 4.6875, "\\": 5.8250, "]": 4.6875, "^": 10.3875, "_": 6.2875, "`": 4.1375, "a": 7.7500, "b": 8.9500, "c": 7.0250, "d": 8.9625, "e": 7.9500, "f": 4.8625, "g": 8.9625, "h": 8.6250, "i": 3.7375, "j": 3.7500, "k": 7.6250, "l": 3.7375, "m": 13.1250, "n": 8.6375, "o": 8.9125, "p": 8.9500, "q": 8.9625, "r": 5.3500, "s": 6.5375, "t": 5.2250, "u": 8.6375, "v": 7.3500, "w": 11.0625, "x": 7.1000, "y": 7.4125, "z": 6.8875, "{": 4.6875, "|": 3.7750, "}": 4.6875, "~": 10.3875 }经过对半角空格宽度的相对计算,得出以下关键数据:
const asciiSizeMap = [1, 1.054, 1.47, 2.154, 1.979, 3.003, 2.937, 0.867, 1.13, 1.13, 1.536, 2.503, 0.813, 1.461, 0.813, 1.443, 1.979, 1.979, 1.979, 1.979, 1.979, 1.979, 1.979, 1.979, 1.979, 1.979, 0.813, 0.813, 2.503, 2.503, 2.503, 1.63, 3.479, 2.377, 2.117, 2.259, 2.572, 1.855, 1.792, 2.509, 2.611, 0.994, 1.337, 2.142, 1.732, 3.298, 2.744, 2.75, 2.066, 2.75, 2.205, 1.949, 1.937, 2.521, 2.283, 3.434, 2.178, 2.036, 2.093, 1.13, 1.404, 1.13, 2.503, 1.515, 0.997, 1.867, 2.157, 1.693, 2.16, 1.916, 1.172, 2.16, 2.078, 0.901, 0.904, 1.837, 0.901, 3.163, 2.081, 2.148, 2.157, 2.16, 1.289, 1.575, 1.259, 2.081, 1.771, 2.666, 1.711, 1.786, 1.66, 1.13, 0.91, 1.13, 2.503] const emojiSize = 4.753 const cjkSize = 3.373 const mathFontSize = 2.12名称 意义 例 注 asciiSizeMap所有 ASCII 可见字符相对于半角空格的宽度比例 A ≈ 2.38,i ≈ 0.90/ emojiSizeEmoji 平均宽度 😺, 🔥, 🧱 约为半角空格的 4.75 倍,接近一个半 CJK 字符 cjkSize中日韩字符(CJK)的平均宽度 “字”、“ア” 约为半角空格的 3.37 倍 mathFontSize数学符号与特殊字符的平均宽度 ±, 全角数学数字 一般介于 ASCII 与 CJK 之间 这些比例值用于计算表格中每一列的视觉宽度(见上文),
例如当 │ dog │ 小狗 │ 中混合中英文字符时,就能根据实际像素比例进行动态补偿,而不是简单地按字符数量来填空格。Emoji
欢迎来到真正的地狱 —— Emoji。
在理想情况下,可以根据每个字符的查到对应的视觉比例进行排版,
但如何确定「一个表情由几个字符组成」?如果尝试遍历带有emoji的字符串,可能会出现奇怪的情况:
在浏览器控制台中执行这几段代码
'😂'.length // 2 '😂'.split('') /** [ "\ud83d", "\ude02" ] */ '👨👩👧👦'.length // 11 '👨👩👧👦'.split('') /** [ "\ud83d", "\udc68", "", "\ud83d", "\udc69", "", "\ud83d", "\udc67", "", "\ud83d", "\udc66" ] */在技术上,Emoji 的逻辑长度和视觉宽度几乎没有任何线性关系。
码点 / 码元 / 字节
快速复习一下 Unicode 几个基本概念:
名称 原文 说明 例 码点 Code Point Unicode 为每个字符分配的编号,如 U+1F602😂概念上等于“字符” 码元 Code Unit 实际在编码中占用的单元,UTF-8 中每个码元是 1 字节 😂 在 UTF-8 中需要 4 个码元 在 utf8 中,每两个码元为一个字符串长度。
有的 Emoji 是单一字符(如 😊),只有一个码点,长度为
2;有的则是由多个码点组合而成,比如「家庭」👨👩👧👦,
实际上是四个 人类 Emoji(👨👩👧👦) + 三个连接符(Zero Width Joiner, ZWJ),共 7 个码点,28 字节,长度为4 * 2 + 3 == 11Emoji 长度
综上,考虑到 Emoji 的情况,要处理复杂的拼接规则并正确根据视觉上显示的字符数进行计算。
碍于篇幅限制,跳过复杂的思考与推导,得到以下代码:
// 参考自 https://blog.jonnew.com/posts/poo-dot-length-equals-two // 包含部分修改与性能优化 function emojiLen(str) { const joiner = "\u200D" const split = str.split(joiner) let count = 0 for (const s of split) { let num = 0 let filtered = "" for (let i = 0; i < s.length; i++) { const charCode = s.charCodeAt(i) if (charCode < 0xFE00 || charCode > 0xFE0F) { filtered += s[i] } } num = Array.from(filtered).length count += num } return Math.ceil(count / split.length) } function isEmoji(code) { return ( (code === 0x200D) || (code >= 0x1F600 && code <= 0x1F64F) || // Emoticons (code >= 0x1F300 && code <= 0x1F5FF) || // Misc Symbols and Pictographs (code >= 0x1F680 && code <= 0x1F6FF) || // Transport and Map (code >= 0x1F1E6 && code <= 0x1F1FF) || // Regional country flags (code >= 0x2600 && code <= 0x26FF) || // Misc symbols (code >= 0x2700 && code <= 0x27BF) || // Dingbats (code >= 0xE0020 && code <= 0xE007F) || // Tags (code >= 0xFE00 && code <= 0xFE0F) || // Variation Selectors (code >= 0x1F900 && code <= 0x1F9FF) || // Supplemental Symbols and Pictographs (code >= 0x1F018 && code <= 0x1F270) || // Various Asian characters (code >= 0x238C && code <= 0x2454) || // Misc items (code >= 0x20D0 && code <= 0x20FF) // Combining Diacritical Marks for Symbols ) }完
抱歉仓促结尾,一年前的草稿到此完结。
本文原计划还有「全角数学字符」「视觉偏移算法」「基础排版引擎」等原创研究内容,但时间过得太久早就忘记当时的思路与感悟。同时在推导过程中隐去了大量细节,欢迎大家在阅读过程中进行查证。
非常抱歉。
本文及包含数据与代码完全原创,以
CC-BY-SA-NC 4.0授权,转载务必告知。之前发的类似技术分析也没人看,可能是因为论坛人太少了。
不过如果这篇能被更多人读到,我会考虑重拾旧稿,把剩下的部分补完。
最后附原始代码,欢迎大家随意改编使用,二次发布请附带本文地址。
原始代码为我某个程序的动态脚本,需要进行某些改编才能调用。
/** * tabel: 表格模式, 对尾部进行排版与填充 * list: 列表模式, 不填充尾部 * @type { "tabel" | "list" } */ const layoutType = "list" /** * normal: 不处理ascii字符 * math: 会将ascii字符替换为等宽数学字符(U+1D670), 例如 𝚖𝚢-𝚙𝚎𝚝𝚙𝚎𝚝 * @type { "normal" | "math" } */ const textStyle = "normal" /** * slilt: 对于溢出的新行在同列换行 * ```text * | right_symm | 对称, 右对称 | * | etry | , 左右对称 | * ``` * syaggered: 交错换行, 目前仅支持两列 * ```text * | right_symmetry | * | 对称, 右对称, 左右对称 | * ``` * @type { "split" | "syaggered" } */ const breakStyle = 'syaggered' // 连接别名的分隔符 const aliaDelimiter = ', ' // 表格左侧长度 const tabelLeftLength = 16 // 表格左侧长度 const tabelRightLength = 22 // 表格前缀 const linePerfix = '│ ' // 表格分隔符 const lineDelimiter = ' │ ' // 表格后缀 const lineSuffix = ' │' // 表格溢出新行前缀 (参与到长度计算, 请确保兼容性) const overflowNewLinePrefix = "- " // 列表前缀 const listPerfix = '> ' // 列表左侧长度 const listHeadLength = 22 // 换行符 const newLine = '\n' // 分组数量 const groupCount = 4 // 分组前缀 const groupPrefix = '模板范围 ' const otherGroupPrefix = '其他模板: ' // ==== 以下为脚本固定常量与正文,请勿随意修改,除非您完全了解其作用 ==== // 分组范围 const groupStartCode = 97 const groupEndCode = 122 const groupRangeSize = Math.ceil((groupEndCode - groupStartCode + 1) / groupCount) // see calculate-ascii-length.json const asciiSizeMap = [1, 1.054, 1.47, 2.154, 1.979, 3.003, 2.937, 0.867, 1.13, 1.13, 1.536, 2.503, 0.813, 1.461, 0.813, 1.443, 1.979, 1.979, 1.979, 1.979, 1.979, 1.979, 1.979, 1.979, 1.979, 1.979, 0.813, 0.813, 2.503, 2.503, 2.503, 1.63, 3.479, 2.377, 2.117, 2.259, 2.572, 1.855, 1.792, 2.509, 2.611, 0.994, 1.337, 2.142, 1.732, 3.298, 2.744, 2.75, 2.066, 2.75, 2.205, 1.949, 1.937, 2.521, 2.283, 3.434, 2.178, 2.036, 2.093, 1.13, 1.404, 1.13, 2.503, 1.515, 0.997, 1.867, 2.157, 1.693, 2.16, 1.916, 1.172, 2.16, 2.078, 0.901, 0.904, 1.837, 0.901, 3.163, 2.081, 2.148, 2.157, 2.16, 1.289, 1.575, 1.259, 2.081, 1.771, 2.666, 1.711, 1.786, 1.66, 1.13, 0.91, 1.13, 2.503] const emojiSize = 4.753 const cjkSize = 3.373 const mathFontSize = 2.12 let indexTexts const thisId = register(info => { return { hidden: true, inRandomList: false, defaultTemplateWeight: 100 } }) on("load", e => { if (thisId !== e.defaultTemplate) return indexTexts = buildIndexString(e.templates) }) on("bot_send", e => { e.responseInForward(true) for (const indexText of indexTexts) { e.response(indexText) e.responseNewParagraph() } }) /** * @param { PetpetTemplateInfo[] } templates * @returns {string[]} */ function buildIndexString(templates) { let resultArr = new Array(groupCount).fill('') let other = '' for (const template of templates) { const metadata = template.metadata if (!metadata || metadata.hidden) { continue } const alias = metadata.alias || [] const aliasStr = alias.length === 0 ? '-' : join(alias, aliaDelimiter) const firstCodePoint = template.id[0].toLowerCase().codePointAt(0) const group = Math.floor((firstCodePoint - groupStartCode) / groupRangeSize) let line switch (layoutType) { case "tabel": line = tabelLine([item(template.id, tabelLeftLength), item(aliasStr, tabelRightLength)]) + newLine break case "list": line = listPerfix + padRight(template.id, listHeadLength, 0, true).content + ' ' + aliasStr + newLine break } if (group < 0) { other += line } else { resultArr[group] += line } } resultArr = resultArr.filter(s => s.length > 0) .map((s, i) => { const start = i * groupRangeSize + groupStartCode return groupPrefix + String.fromCodePoint(start - 32) + ' - ' + String.fromCodePoint(Math.min(groupEndCode, start + groupRangeSize - 1) - 32) + ': ' + newLine + s }) if (other) { resultArr.push(otherGroupPrefix + other) } return resultArr } function tabelLine(items) { switch (breakStyle) { case "split": return lineSplit(items) case "syaggered": return lineSyaggered(items) default: throw Error("breakStyle 变量参数错误") } } function lineSyaggered(items) { if (items.length !== 2) { throw Error("syaggered break item length must == 2"); } let result = ''; const padder0 = padRight(items[0][0], items[0][1]); const padder1 = padLeft(items[1][0], items[1][1], padder0.offset); let lineLen = items[1][1]; if (padder0.overflow || padder1.overflow) { lineLen = items[0][1] + items[1][1] + lineDelimiter.length; result += linePerfix + syaggerePadder(items[0][0], lineLen, 0, true) + lineSuffix + newLine + linePerfix; } else { result += linePerfix + padder0.content + lineDelimiter; } if (padder1.overflow) { const prefix = padder0.overflow ? '' : overflowNewLinePrefix; result += syaggerePadder(prefix + items[1][0], lineLen, padder0.overflow ? 0 : padder0.offset, false) + lineSuffix; } else { if (padder0.overflow) { result += syaggerePadder(overflowNewLinePrefix + items[1][0], lineLen, 0, false) + lineSuffix; } else { result += padder1.content + lineSuffix; } } return result; } function syaggerePadder(str, len, offset = 0, isLeft = true) { let padFun = isLeft ? padRight : padLeft let padder = padFun(str, len, offset) let result = padder.content if (padder.overflow) { result += newLine + linePerfix + syaggerePadder(padder.overflow, len, padder.offset, isLeft) + lineSuffix } return result } function lineSplit(items) { let result = linePerfix let offset = 0 let overflows = [] for (let i = 0; i < items.length; i++) { const item = items[i] const padder = padRight(item[0], item[1], offset) offset = padder.offset if (padder.overflow) overflows[i] = padder.overflow result += padder.content if (i != items.length - 1) { result += lineDelimiter } } result += lineSuffix if (overflows.length > 0) { const overflowItems = items.map((it, i) => item(overflows[i] || ' ', it[1])) result += newLine + lineSplit(overflowItems) } return result } function item(str, length) { return [str, length] } function prePad(str, length) { if (textStyle === "math") { str = convertToMathCharacters(str) } let charIndex = 0 let displayLen = 0 let emojis = '' const chars = Array.from(str) for (let i = 0; i < chars.length; i++) { const codePoint = chars[i].codePointAt(0) let add = 0 if (isMathCaracter(codePoint)) { // 因为默认替换的原因, 数学字符命中率最高 if (emojis) { add += emojiLen(emojis) * emojiSize emojis = '' } add += mathFontSize // Full-width Math characters } else if (isEmoji(codePoint)) { emojis += String.fromCodePoint(codePoint) } else { if (codePoint >= 0x0020 && codePoint <= 0x7F) { add = asciiSizeMap[codePoint - 32] || 0 // ASCII characters } else if (codePoint >= 0x80 && codePoint <= 0x1FFF) { add = 1 // Half-width characters } else if (codePoint >= 0x2000 && codePoint <= 0xFF60) { add = cjkSize // Full-width CJK characters } else if (codePoint >= 0xFF61 && codePoint <= 0xFF9F) { add = 1 // Half-width katakana } else if (codePoint >= 0xFFA0) { add = 2 // Full-width characters } if (emojis) { add += emojiLen(emojis) * emojiSize emojis = '' } } if (i === chars.length - 1 && emojis) { add += emojiLen(emojis) * emojiSize emojis = '' } if (Math.round(displayLen) + add > length) { break } displayLen += add charIndex++ } return { str, displayLen, chars, charIndex } } function padLeft(str, length, offset = 0) { const p = prePad(str, length) str = p.str const resultLen = Math.round(p.displayLen + offset) const spaces = ' '.repeat(Math.max(length - resultLen, 0)) if (p.chars.length <= p.charIndex) { return { content: spaces + str, offset: p.displayLen - resultLen } } else { let result = p.chars.slice(0, p.charIndex).join('') return { content: spaces + str, offset: p.displayLen - resultLen, overflow: str.substring(result.length) } } } function padRight(str, length, offset = 0, allowOverflow = false) { const p = prePad(str, length) str = p.str const resultLen = Math.round(p.displayLen + offset) const spaces = ' '.repeat(Math.max(length - resultLen, 0)) if (p.chars.length <= p.charIndex || allowOverflow) { return { content: str + spaces, offset: p.displayLen - resultLen } } else { let result = p.chars.slice(0, p.charIndex).join('') return { content: result + spaces, offset: p.displayLen - resultLen, overflow: str.substring(result.length) } } } // by https://blog.jonnew.com/posts/poo-dot-length-equals-two function emojiLen(str) { const joiner = "\u200D" const split = str.split(joiner) let count = 0 for (const s of split) { let num = 0 let filtered = "" for (let i = 0; i < s.length; i++) { const charCode = s.charCodeAt(i) if (charCode < 0xFE00 || charCode > 0xFE0F) { filtered += s[i] } } num = Array.from(filtered).length count += num } return Math.ceil(count / split.length) } function isEmoji(code) { return ( (code === 0x200D) || (code >= 0x1F600 && code <= 0x1F64F) || // Emoticons (code >= 0x1F300 && code <= 0x1F5FF) || // Misc Symbols and Pictographs (code >= 0x1F680 && code <= 0x1F6FF) || // Transport and Map (code >= 0x1F1E6 && code <= 0x1F1FF) || // Regional country flags (code >= 0x2600 && code <= 0x26FF) || // Misc symbols (code >= 0x2700 && code <= 0x27BF) || // Dingbats (code >= 0xE0020 && code <= 0xE007F) || // Tags (code >= 0xFE00 && code <= 0xFE0F) || // Variation Selectors (code >= 0x1F900 && code <= 0x1F9FF) || // Supplemental Symbols and Pictographs (code >= 0x1F018 && code <= 0x1F270) || // Various Asian characters (code >= 0x238C && code <= 0x2454) || // Misc items (code >= 0x20D0 && code <= 0x20FF) // Combining Diacritical Marks for Symbols ) } function isMathCaracter(code) { return (code >= 0x1D670 && code <= 0x1D6A3) || // A - z (code >= 0x1D7F6 && code <= 0x1D7FF) // 0 - 9 } function convertToMathCharacters(input) { let result = '' for (const ch of input) { const code = ch.charCodeAt(0) if (code >= 65 && code <= 90) { result += String.fromCodePoint(0x1D670 + (code - 65)) } else if (code >= 97 && code <= 122) { result += String.fromCodePoint(0x1D68A + (code - 97)) } else if (code >= 48 && code <= 57) { result += String.fromCodePoint(0x1D7F6 + (code - 48)) } else { result += ch } } return result } // ==== 以下内容为 Nashorn 兼容性方案,请勿将其视为无用代码而删除,除非您确认此脚本可在指定引擎上正常运行 ==== function join(array, separator) { if (array.join) { return array.join(separator) } let result = '' for (let i = 0; i < array.length; i++) { if (i > 0) { result += separator } result += array[i] } return result } /** * https://github.com/efwGrp/nashorn-ext-for-es6 * The String.fromCodePoint() static method returns a string created from the specified sequence of code points. * ECMAScript 2015 */ if (!String.fromCodePoint) { String.fromCodePoint = function fromCodePoint() { var chars = [], point, offset, i var length = arguments.length for (i = 0; i < length; ++i) { point = arguments[i] if (point < 0x10000) { chars.push(point) } else { offset = point - 0x10000 chars.push(0xD800 + (offset >> 10)) chars.push(0xDC00 + (offset & 0x3FF)) } } return String.fromCharCode.apply(null, chars) } Object.defineProperty(String, "fromCodePoint", { enumerable: false }) } if (!Array.from) { Array.from = function (r, u, e) { let l = [] for (let n of r) null != u ? null != e ? l.push(u.call(e, n)) : l.push(u(n)) : l.push(n) return l } Object.defineProperty(Array, "from", { enumerable: false }) } if (!Array.prototype.fill) { Array.prototype.fill = function (value, start = 0, end = this.length) { const length = this.length let startIndex = Math.max(0, start < 0 ? length + start : start) let endIndex = Math.min(length, end < 0 ? length + end : end) for (let i = startIndex; i < endIndex; i++) { this[i] = value } return this } }效果预览
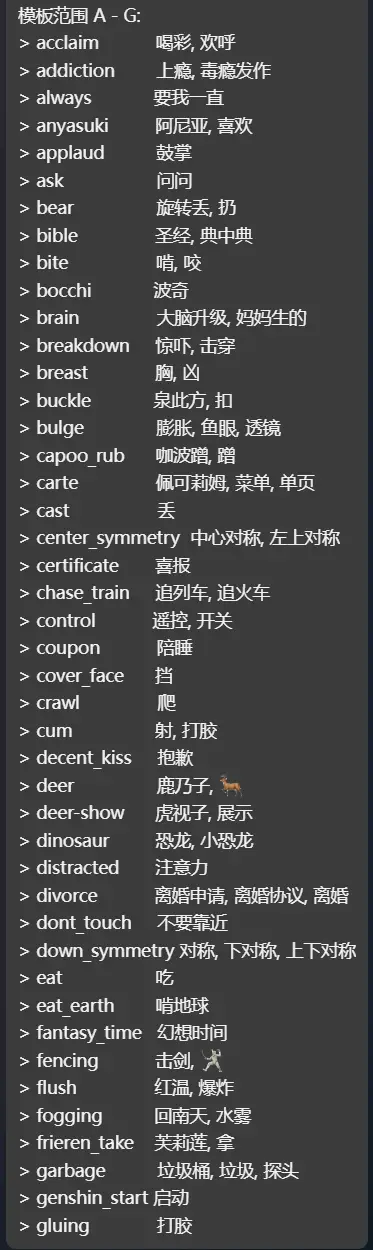
完结烂尾撒花
-
【水】被封群11次/封号约50次后,对腾讯谜之审核机制的吐槽发布在 摸鱼区
新群活了不到一个月 又被封了
从三年前开始,换过约8个QQ账号,分别来自不同的群友借我的小号 无一例外都被封禁 1-3 个月或永久
群聊也被封过11次,每次都是重新邀请群友开新群
以下为某个账号的封禁历史,战绩可查

- 群里从不建政,发色图频率极低
- 每个群存活时间随机,2周-9个月 不等
- 每周目群人数约90人
以下是关于腾讯审核机制的推测:
- 发色图时会被腾讯的AI检测一遍,如果别人能看到发送的图像则说明检测通过;文字消息不会被检测
- 被举办后会交给更聪明的AI检测,如果检测成功则提示「你的账号____已被他人举报」
- AI无法处理的会由人工审核,被封禁提示「经平台检测____限制使用部分产品功能」
- 文字谐音等规避审查的方式也会被检测,例如「扔子」「小学」等
封号机制:
- 被封号后无法发言,进行同意入群申请,修改群设置等操作
- 通常来说,前3次封号可马上解封,第4/5次封禁一天,之后每次封禁 7天/1个月/3个月/永久,与账号风控等级有关
- 封号后手机端个人资料会被隐藏
TIPS:
被封群后不用慌,NTQQ右键将被封的群消息标记为未读,再点击右下角托盘的闪烁图标即可看到全部群友名单,可复制QQ号
-
jvm awt 图像处理入坑/退坑指南发布在 摸鱼区
前言
作为合格的 Miraier,一定曾想过在插件中加入图像合成功能,例如绘制每日发言排行榜,漂亮的签到卡片,
或只是想给色图加个滤镜避免被 QQ 服务器吃掉。开始进行图像处理的第一步当然是选择合适的 API,
选择比努力更重要在 JVM 平台上,有几个主流的图形处理方案可以选择:
Skia
谷歌家的大小姐,地球上最流行的图形API,广泛应用于 Chromium、Android、Flutter 等知名软件中。
虽然笔者并未在 JVM 平台上直接使用过 Skia,但以下总结的优势来自于笔者在 Rust-Skia 中的经验:
- 性能:支持 GPU 加速,并允许编写 GPU 着色器(使用类似 GLSL 的 SKSL 语法)。
- 漂亮:相比于调教不足的 AWT,Skia 渲染的图像无需额外调教就十分精甚细腻。
Skia 在 JVM 平台上的短板也很明显:
- JNI:每个平台和架构都需要单独分发代码,且本地库编译后的文件大小约为 10MB。
- 文档:网上很难找到针对特定问题的 Java 绑定解决方案,相关的第三方库也很少。
- 编译:如果想要使用 Skia 的扩展功能(如 SVG 段落排版等),不得不经历一场痛苦的编译与配置过程,而且为每个平台交叉编译的方式与 JVM 平台的开发习惯并不匹配。
JavaFX
十分古老的新技术,适合构建 UI 应用,文档和第三方库非常稀缺,因此后文不再提及。
AWT
作为 JDK 的一部分,AWT 是 Java 中最为流行的图形 API,无需额外依赖,基于 AWT 的知名软件包括 JetBrains 全家桶 和 Eclipse。
与 Skia 相比,AWT 的优势如下:
- 生态:AWT 长期以来是 Java UI 和图像处理的唯一选择,因此可以找到详尽的文档资料,调教指南与第三方库(例如本文)。
- 依赖:捆绑在几乎所有 jvm 中,无需额外依赖。
又不能选装,不用白不用
劣势也很明显:
- 古老:AWT 不支持许多现代特性,例如彩色 emoji 字体和亚像素级抗锯齿等。
- 性能:编写高性能的代码需要付出大量的努力,尤其是在 AWT 中。
- 欠草:渲染漂亮图像的过程中会遇到许多迷惑的历史遗留特性,需要加大力度调教,这也是本文诞生的原因之一。
总而言之,笔者强烈推荐大家选择 Skia。如果您不幸入坑了 AWT,希望本文能帮助你避开一些常见的坑。
AWT 七宗罪
锯齿
在 AWT 诞生的年代,给文本和图片加上抗锯齿会严重降低性能,后来为了保证和之前版本的一致性,抗锯齿选项也没有默认启用。
g2d.setRenderingHint( RenderingHints.KEY_ANTIALIASING, RenderingHints.VALUE_ANTIALIAS_ON); g2d.setRenderingHint( RenderingHints.KEY_INTERPOLATION, RenderingHints.VALUE_INTERPOLATION_BILINEAR); g2d.setRenderingHint( RenderingHints.KEY_RENDERING, RenderingHints.VALUE_RENDER_QUALITY); g2d.setRenderingHint( RenderingHints.KEY_STROKE_CONTROL, RenderingHints.VALUE_STROKE_PURE); g2d.setRenderingHint( RenderingHints.KEY_TEXT_ANTIALIASING, RenderingHints.VALUE_TEXT_ANTIALIAS_ON); g2d.setRenderingHint( RenderingHints.KEY_ANTIALIASING, RenderingHints.VALUE_ANTIALIAS_ON); g2d.setRenderingHint( RenderingHints.KEY_RENDERING, RenderingHints.VALUE_RENDER_QUALITY);
以上选项仅适用于文本与 Shape 抗锯齿,您会发现图片缩放绘制时还是会有锯齿和奇怪的像素点,这时就要说到...
重采样
-
drawImage想象一下这段代码
g2d.drawImage(img, x, y, w, h, null);这几乎是 AWT 中最常见的绘制图像操作,虽然速度很快,但对于缩放图像来说效果是相当糟糕的。

所幸 AWT 中还有更漂亮的方法:
-
getScaledInstanceimg.getScaledInstance(w, h, Image.SCALE_SMOOTH);
确实漂亮了很多,然而代价是性能损失了几乎 1000 倍甚至 900 倍,在基准测试中,上个方法耗时为
0ms,这个方法耗时771ms,很显然也是不能接受的。可以看出,AWT 对图像的缩放算法相当糟糕,还好我们有更现代的第三方库:
-
Thumbnails.sizeThumbnails.of(image).size(w, h).asBufferedImage();
得益于第三方库实现的快速重采样算法,缩放这张图片只花费了
94ms -
回到
drawImage在缩放图像分辨率与实际绘制分辨率相近的情况下,使用
Thumbnails.size反而会造成额外的性能开销,经过古人的实践与总结,缩放倍率在 0.5 以内使用drawImage是最优解,超过此倍率就要引入额外的缩放流程来保证质量。举例:
当原始分辨率为
200 * 200时, 缩放到101 * 101或299 * 299应使用drawImage; 缩放到99 * 99或301 * 301应加入额外的缩放流程。 -
网络请求 【Miraier 限定】 【腾讯粉丝福利】
聪明的 Miraier 应该也想到了从网络请求入手,请求更低分辨率的图像,既能减少图片下载时间又能提升缩放时的性能。
这是 Mirai 源码中获取用户头像的代码
public interface ContactOrBot : CoroutineScope { /** * 头像下载链接, 规格默认为 [AvatarSpec.LARGEST] */ public val avatarUrl: String get() = avatarUrl(spec = AvatarSpec.LARGEST) /** * 头像下载链接. * @param spec 头像的规格. */ @JvmName("getAvatarUrl") public fun avatarUrl(spec: AvatarSpec): String { return "http://q.qlogo.cn/g?b=qq&nk=${id}&s=${spec.size}" } }另外,域名为 gchat.qpic.cn 的图像貌似也可以请求低分辨率版本,但笔者没有在网上找到更多信息,希望大佬跟帖补充。
上文图像与基准测试引用自 Thumbnailator/wiki
文字排版
研表究明,99% 的 AWT 用户在第一次绘制文本多行文本时,一定会写出这段代码:
g2d.drawString("多行\n文本", 20, 30);虽然几乎所有的图形 API 都会有这个问题,但 AWT 的高级排版类(例如
FlowLayout)是 Swing UI 专属,无法直接在图像内绘制文字。在 Skia 中可以使用段落扩展来快速实现排版,AWT 又输
例如,在 AWT 中使用
LineBreakMeasurer和TextLayout计算坐标实现基本的文本溢出换行:public void paint(Graphics graphics) { Point2D pen = new Point2D(10, 20); Graphics2D g2d = (Graphics2D)graphics; FontRenderContext frc = g2d.getFontRenderContext(); LineBreakMeasurer measurer = new LineBreakMeasurer(styledText, frc); float wrappingWidth = getSize().width - 15; while (measurer.getPosition() < fStyledText.length()) { TextLayout layout = measurer.nextLayout(wrappingWidth); pen.y += (layout.getAscent()); float dx = layout.isLeftToRight() ? 0 : (wrappingWidth - layout.getAdvance()); layout.draw(graphics, pen.x + dx, pen.y); pen.y += layout.getDescent() + layout.getLeading(); } }(更多示例请参考 甲骨文官方文档)
当然,上方的代码只是甲骨文的卖家秀,实际渲染环境中没机会写出这么简洁的代码,因为会碰到更头痛的问题:
字体回退
想象这样一个场景:
var font = StyleContext.getDefaultStyleContext().getFont("漂亮的英文字体", Font.PLAIN, 24); g2d.setFont(font); g2d.drawString("Hello 世界!", 20, 30);上方代码在 Windows 和 Linux 平台上会渲染为 【Hello 口口口】,在 Mac 平台上会正常渲染。
造成这种差异的原因是 JVM 逻辑字体配置
fontconfig.properties,仅在某些平台上生效,深层次的原因是 AWT 在不支持的平台上使用旧版本 HarfBuzz 进行整形,并不会自动回退为支持的字体。对于这种情况的解决方案:
-
强迫用户使用 MacOS
-
强迫用户改用 JetBrainsRuntime JVM
-
自己实现字体回退逻辑:
例:
Font mainFont = StyleContext.getDefaultStyleContext().getFont("漂亮的英文字体", Font.PLAIN, 24); Font fallbackFont = StyleContext.getDefaultStyleContext().getFont("回退的中文字体", Font.PLAIN, 24); AttributedString str = new AttributedString("Hello 世界!"); int textLength = text.length(); result.addAttribute(TextAttribute.FONT, mainFont, 0, textLength); boolean fallback = false; int fallbackBegin = 0; for (int i = 0; i < text.length(); i++) { boolean curFallback = !mainFont.canDisplay(text.charAt(i)); if (curFallback != fallback) { fallback = curFallback; if (fallback) { fallbackBegin = i; } else { result.addAttribute(TextAttribute.FONT, fallbackFont, fallbackBegin, i); } } } g2d.drawString(str.getIterator(), 20, 30);聪明的读者一定已经发现:
上文中
LineBreakMeasurer ()构造函数刚好需要str.getIterator()获取的AttributedCharacterIterator!
将两段代码结合一下刚好能实现最基础的文本段落渲染。
全局字体
看到这里,大部分爱偷懒的 Miraier 都会想到【回退字体也太麻烦了,直接用中文字体渲染就好了】偷懒方案可跳转至下文 #偷懒的最终方案
这会导致以下问题:
- 无法渲染字体不支持的字符,例如 阿拉伯语,印地语 等。
- 无法同时用漂亮的英文字体和中文字体回退。
- 无法渲染 Emoji (很多用户的 ID 包含 Emoji,不能渲染的话就太糟了)
于是诞生了终极方案:
- 默认字体无法显示,启用回退方案。
- 调用
GraphicsEnvironment.getLocalGraphicsEnvironment().getAllFonts()取得注册的所有字体进行遍历。 - 找到能显示的字体应用到字符。
程序初始化时通过测试各语言码点分类进行性能优化:
- 遍历所有字体并测试各语言覆盖范围,例如
AB00-AB5F范围为越南傣语,测试字体是否支持AB00 - 渲染时快速判断字符码点范围查表找出回退字体
需要注意的是:
-
Emoji 和部分扩展区字符会占用多个码点,超出 char 的范围,例如 Emoji
😊为Character.toChars(0x1F600) -
Emoji 可能包含连字符
0x200d, 被连字符组合的 Emoji 不应该被分开渲染,例如👩👩👧👧包含 4 个子表情与 3 个连字符,占用 11 个 char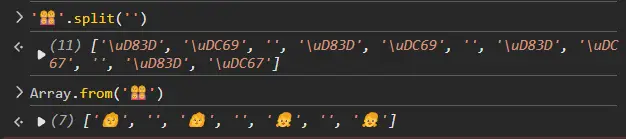
Emoji 没有颜色😭

遗憾的是, AWT 使用的 HarfBuzz 版本不支持 CPAL, SBIX 等彩色字体扩展,只能通过定制 JVM 并替换 HarfBuzz 依赖解决。
万幸,JetBrains 在开发 IDE 时注意到了这点,目前在 AWT 平台渲染彩色 Emoji 唯一的解决方案是使用 JetBrainsRuntime JVM。
偷懒的最终方案
在 AWT 中,可以使用
"Dialog"获取当前系统字体, 而且在任何平台都能正确应用 JVM 逻辑字体配置fontconfig.properties中定义的回退方案。没有调用 g2d.setFont() 时绘制的文字也会使用
"Dialog"字体var font = StyleContext.getDefaultStyleContext().getFont("Dialog", Font.PLAIN, 24); g2d.setFont(font);作为偷懒的惩罚,使用自定义字体时不支持的字符会变为 【口口口】,详见上文。
后话
本来想写的 AWT 七宗罪只写了四条,请期待本贴持续更新。
最后,以上提到的几点在 Skia 中完全无需任何调教,笔者强烈推荐大家选择 Skia。
本贴欢迎提问 AWT 与 Rust-Skia 相关问题,别的我也不会。
本文随意转载,转载前请告知我。
CC-BY-NC-SA 4.0
相关链接: Petpet

