语音生成功能+自定义回复
-
@NakiriToki 我查了一下,这个报错是由于你的计算机硬件不支持NNPACK指令集,先看看生成的语音能否正常播放。
-
@lunailoli
希望自定义触发指令的话需要修改voicePart.py文件,如果有自定义触发指令需求可以留言。 -
@Anstiya
语音可以正常播放,程序是在linux 服务器上运行的 系统是CentOS 8.0试着按chatgpt的说法
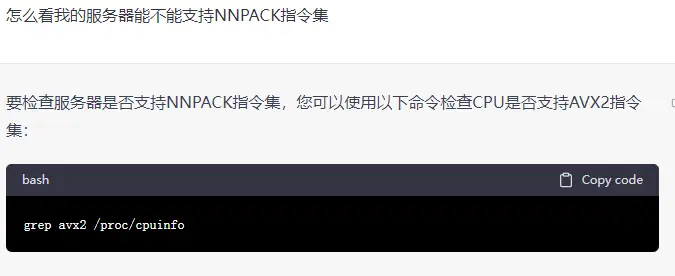
似乎cpu是支持的 -
@NakiriToki 目前这个项目没法在linux部署(有老哥试过了),或许是linux版python的某些库与window的不同,但我不熟悉linux系统😂,或许以后有带佬能解决这个问题。
不过既然语音可以正常播放说明或许合成过程没有问题(能跑就行),问题出在语音的发送阶段,这里随后我看看能不能解决。 -
@Anstiya 了解了ORZ
-
@Anstiya 我去开了个issue
-
@lunailoli 刚意识到说的是词库功能自定义命令😂,这个最近我尝试了思知ai,可以把词库导入进思知ai的知识库,相应的api调用目前没有限制;另外思知的jiagu库匹配精准度要高于fuzzywuzzy,所以随后词库这块会重做,加入自定义指令的话也不错。
-
非常抱歉打扰大佬,我在其他地方获取的vits训练模型在这里不知如何正确配置 恳请大佬指教T_T
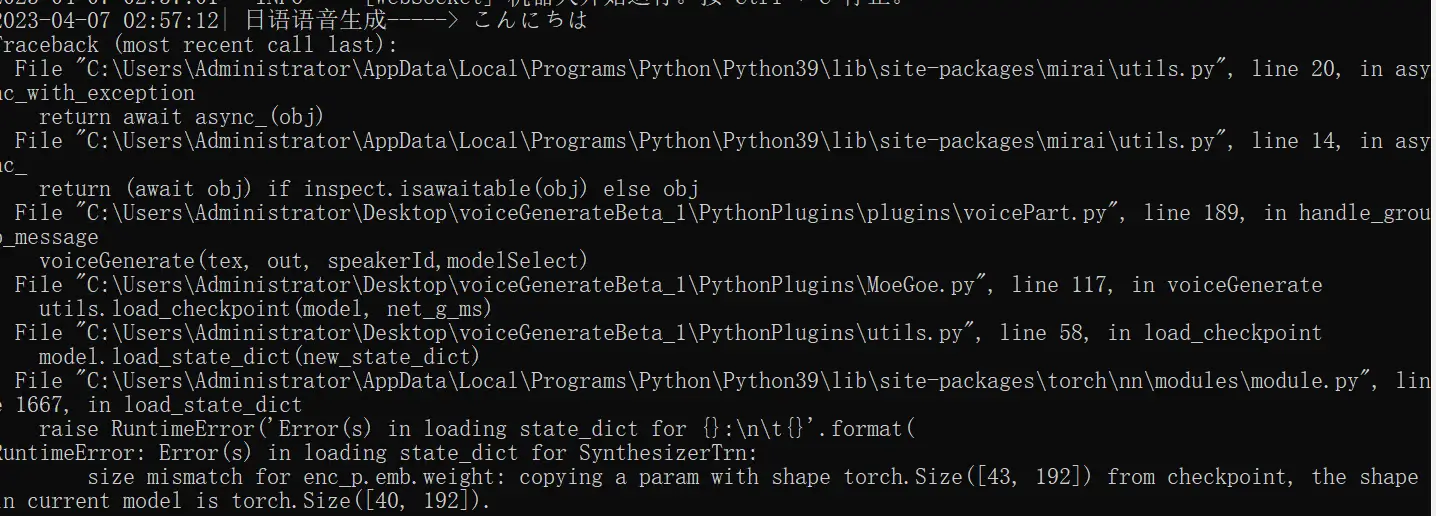
(↓除了speakers和symbols,都是已经自带的配置){ "train": { "log_interval": 200, "eval_interval": 4000, "seed": 1234, "epochs": 10000, "learning_rate": 2e-4, "betas": [0.8, 0.99], "eps": 1e-9, "batch_size": 32, "fp16_run": true, "lr_decay": 0.999875, "segment_size": 8192, "init_lr_ratio": 1, "warmup_epochs": 0, "c_mel": 45, "c_kl": 1.0 }, "data": { "training_files":"filelists/mmj_train.txt.cleaned", "validation_files":"filelists/mmj_val.txt.cleaned", "text_cleaners":["japanese_cleaners2"], "max_wav_value": 32768.0, "sampling_rate": 22050, "filter_length": 1024, "hop_length": 256, "win_length": 1024, "n_mel_channels": 80, "mel_fmin": 0.0, "mel_fmax": null, "add_blank": true, "n_speakers": 4, "cleaned_text": true }, "model": { "inter_channels": 192, "hidden_channels": 192, "filter_channels": 768, "n_heads": 2, "n_layers": 6, "kernel_size": 3, "p_dropout": 0.1, "resblock": "1", "resblock_kernel_sizes": [3,7,11], "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]], "upsample_rates": [8,8,2,2], "upsample_initial_channel": 512, "upsample_kernel_sizes": [16,16,4,4], "n_layers_q": 3, "use_spectral_norm": false, "gin_channels": 256 }, "speakers": ["\u0061\u006b\u0069\u0074\u006f","\u0061\u006e","\u006b\u006f\u0068\u0061\u006e\u0065","\u0074\u006f\u0079\u0061"], "symbols": ["_", ",", ".", "!", "?", "-", "A", "E", "I", "N", "O", "Q", "U", "a", "b", "d", "e", "f", "g", "h", "i", "j", "k", "m", "n", "o", "p", "r", "s", "t", "u", "v", "w", "y", "z", "\u0283", "\u02a7", "\u2193", "\u2191", " "] }模型下载地址
因为我对这方面完全没有经验,但想用上大佬的工具,再一次恳请得到大佬的帮助和指教T_T -
@Anstiya
今天拿windows试了一下,发现是我mirai上装了mirai-silk-converter 这个插件的缘故
mirai-silk-converter
本来是想着提前转音频格式让pc也能正常听到结果好像搞砸了ORZ
把这个插件卸载之后我linux服务器上也能成功运行了
之后就期待大佬能实现pc端正常播放了 -
佬,怎么定义它能使用的群组锕,它每个群都会读取到,还有私聊也是
-
@EternityTQ 抱歉最近没有看论坛消息,下午我会尝试这个模型。
-
@ATRI 所有群都可用,私聊的话语音都是没声音的。原因不确定,可能是私聊的语音有不同的加密方式。
-
在pip步骤就失败了……OpenCC死活装不了
-
这个问题如何解决
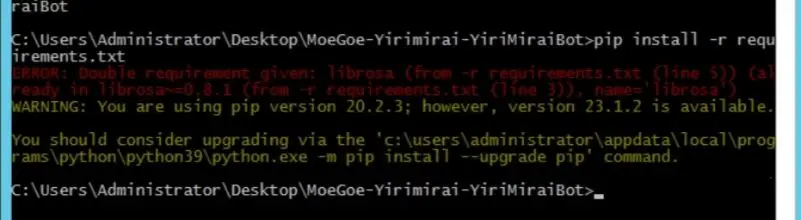
-
@幻空zzz 红字看不太清,先更新个pip看看吧。
-
@ShadowScale release有site_packages试试直接文件夹整体替换。
-
@Anstiya 更新了之后的报错
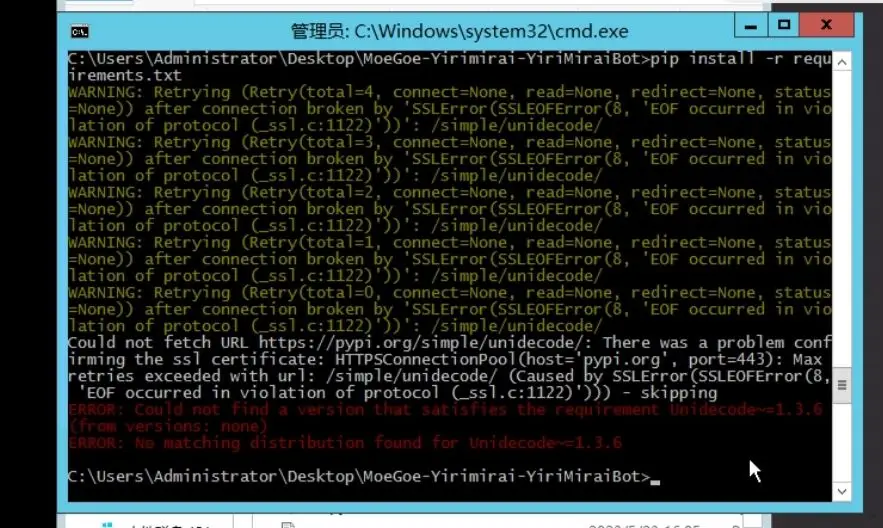 这次的红字是
这次的红字是
ERROR: Could not find a version that satisfies the requirement Unidecode~1.3.6(from versions: none)
ERROR: No matching distribution found for Unidecode~=1.3 , 6 -
@幻空zzz
似乎有网络连接问题,先试试换源命令
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple
换源后重新执行
pip install -r requirements.txt如依然有问题
cmd中执行
pip install Unidecode==1.3.6
失败的话就不指定版本了,执行
pip install Unidecode -
@Anstiya OK解决了,感谢
-
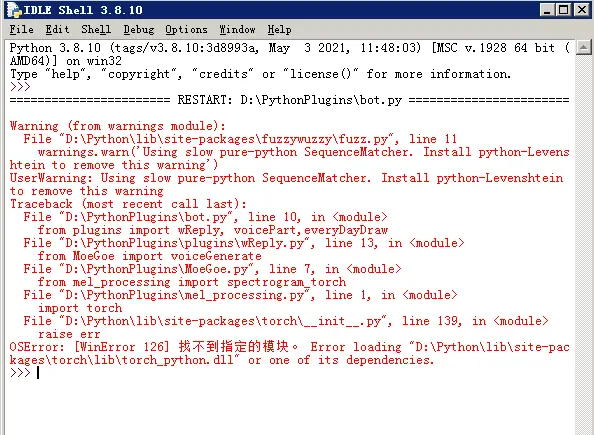
出现了新的问题