语音生成功能+自定义回复
-
请问一下怎么查看语音模型的Unicode呢 从b站那边下载下来的模型里大部分只有总和的的config 想安装全部的碧蓝角色模型 虽然有看见大佬给前面的回复解答 但还不是很明白 能详细讲讲单独一个角色的config修改方式吗
-
@半冬芯Chaki
以碧蓝档案的模型库为例
碧蓝档案模型库的模型大都是单角色,它的配置文件是多模型通用的,但为了更方便地使用,我们需要修改config.json
在这个网站把角色的名称转成对应的unicode编码
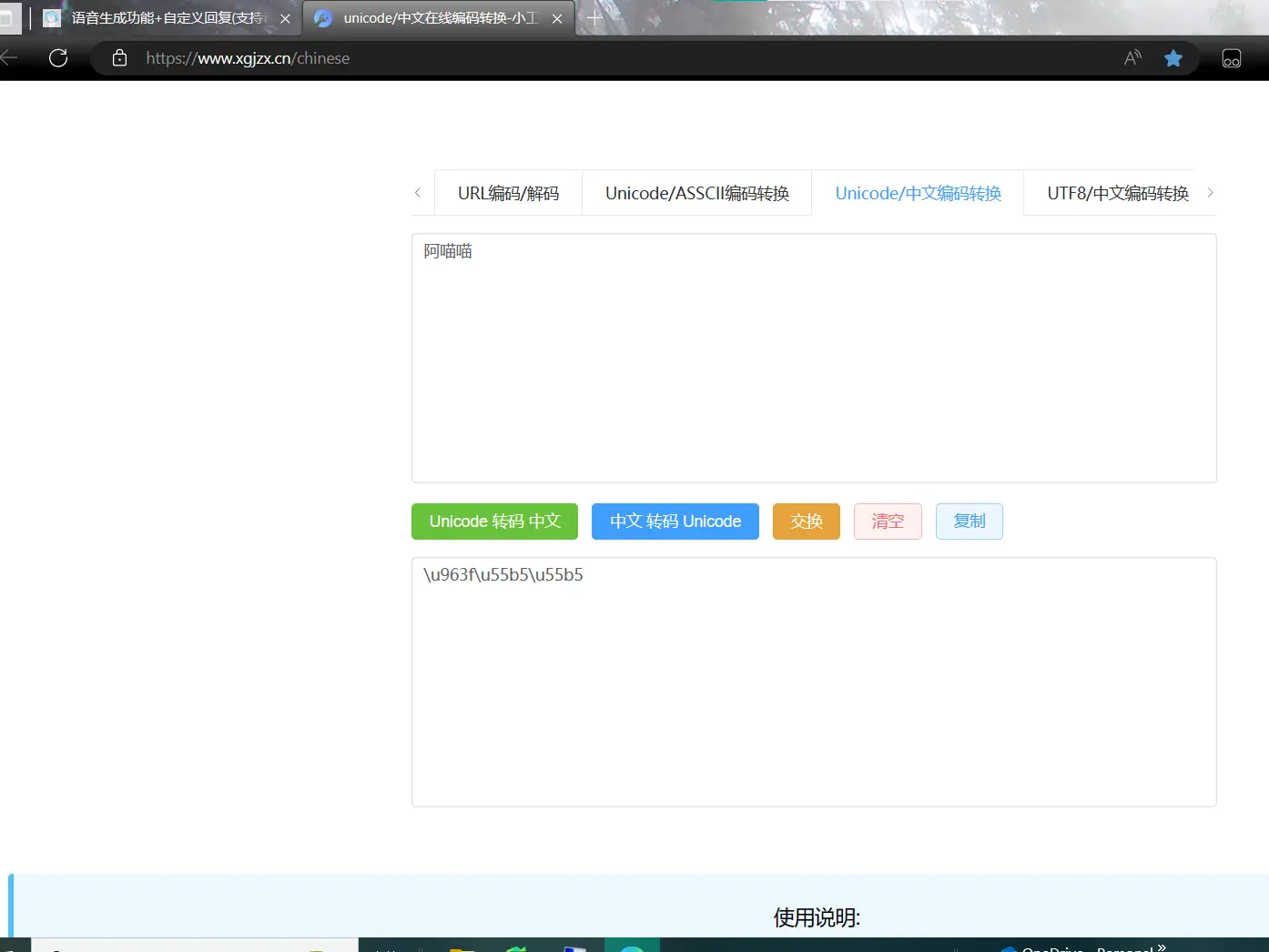
打开config.json文件,把上一步得到的角色名称的unicode码填入speakers项。
修改前:"speakers":["这里是一大堆东西,全删掉"]
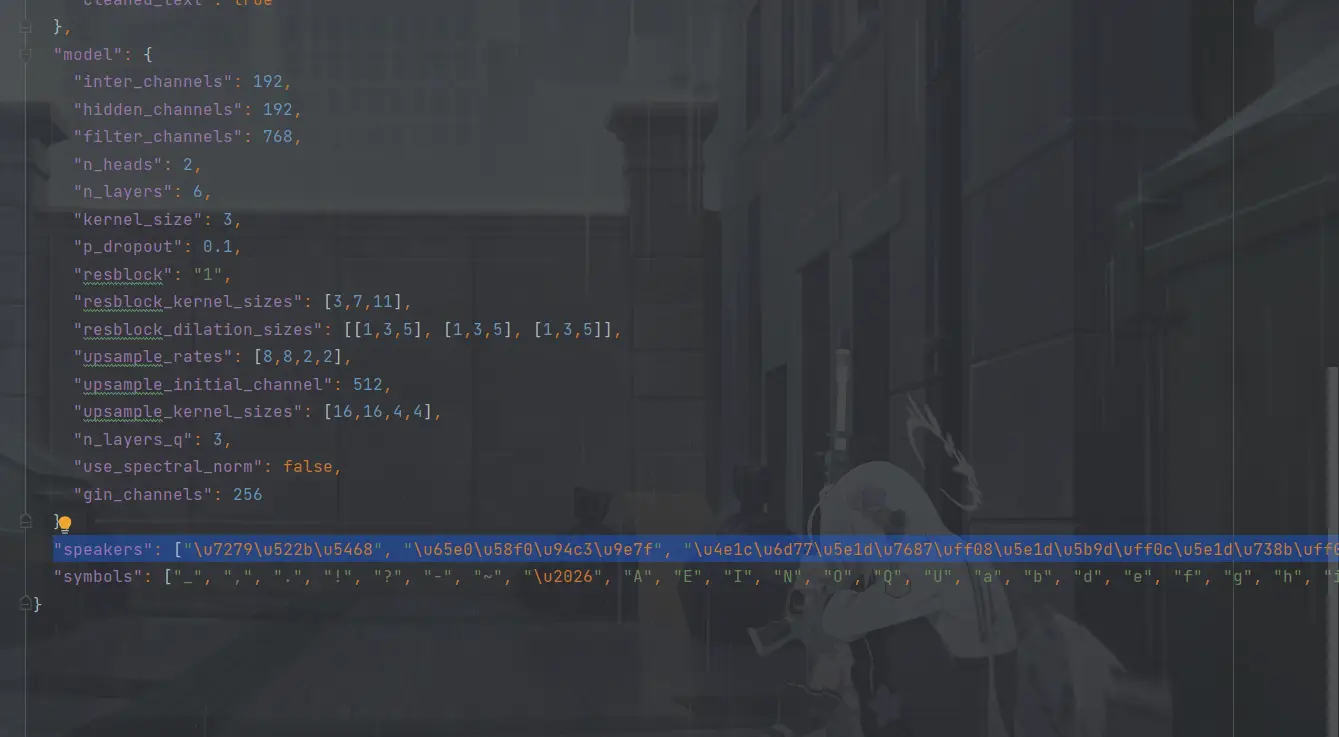
修改后如图
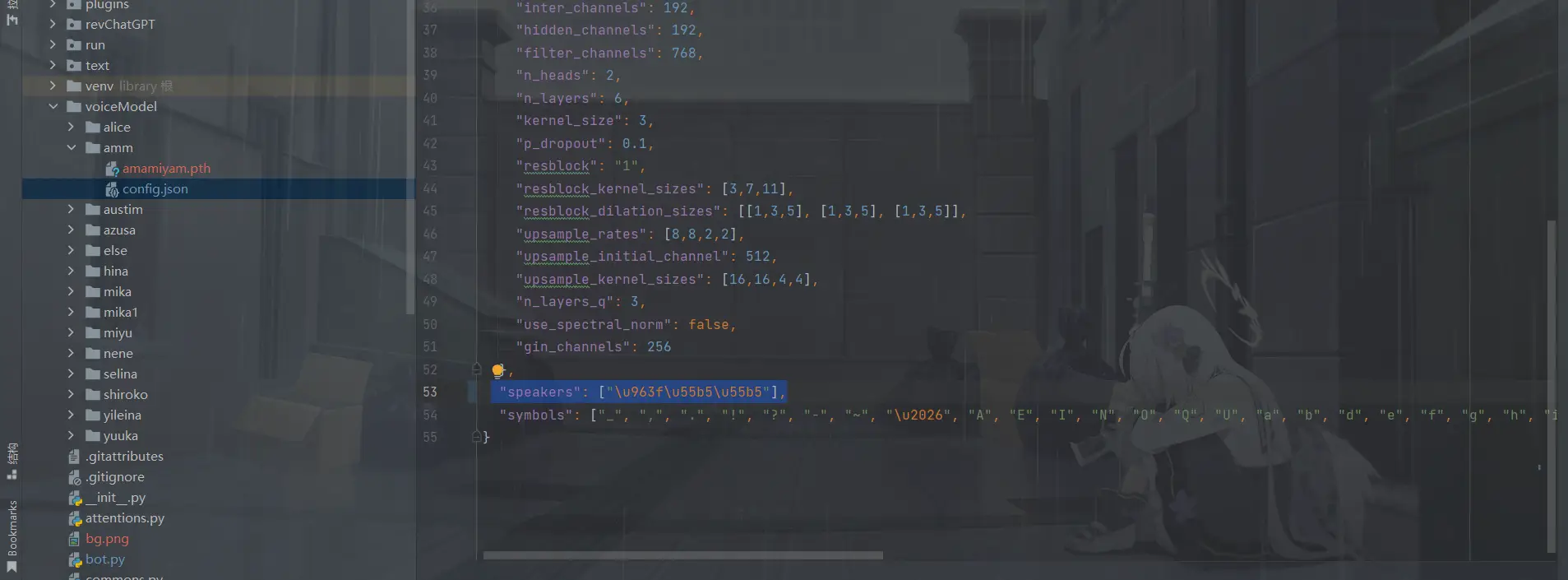
需要注意
如果模型支持中日双语则需要把模型名从XXX.pth改成XXXm.pth之后就可以在群里执行
阿喵喵说我可否将你比作一个夏日……没什么,只是一段诗歌而已。
阿喵喵中文我可否将你比作一个夏日……没什么,只是一段诗歌而已。
阿喵喵日文貴方を夏の一日に例えてみましょうか…なんでもありません、ただの独り言です。 -
明白了 十分感谢 我这就去试试!
-
This post is deleted! -
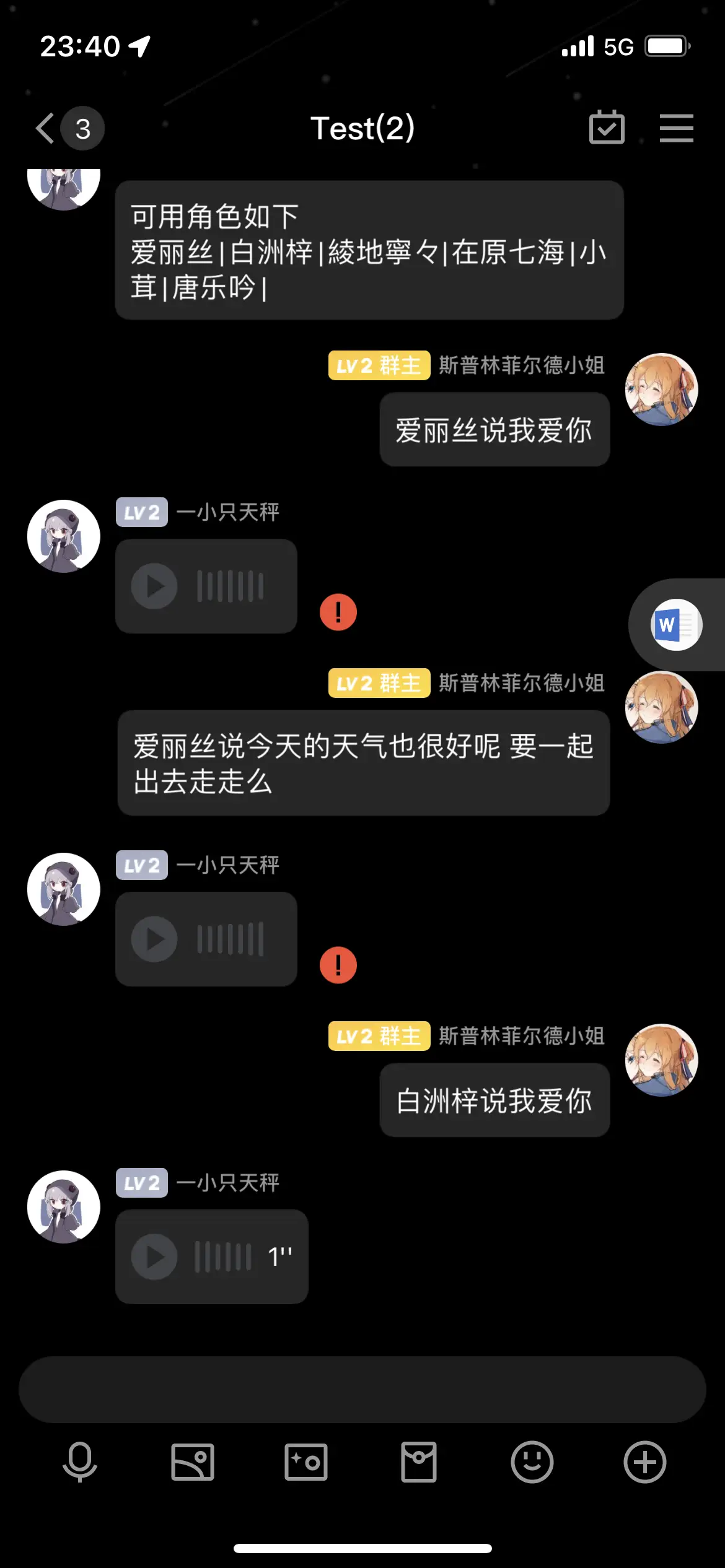
按照大佬的方法试了一会 修改了爱丽丝和日奈的config 好像只有爱丽丝的能识别出来 而且群里收到的语音变成了红色感叹号 也按照前面的回答替换了release里的 MoeGoe.py 但还是不行 只有之前的梓宝是能正常运作的 能麻烦大佬再看一下么
![]SRBMTDSXUD$]6@$P5V8WB.png](/assets/uploads/files/1678204253480-srbmtdsxud-6-p-96-5v8wb.png) 
-
@半冬芯Chaki 每个模型在voiceModel文件夹下要有一个单独的文件夹和以及config.json。后台有报错的话看看后台的报错
-
This post is deleted! -
-
-
我上面有传后台的图片好像没识别出来,目录结构这块应该是没有问题的,已经对着替换过多次,等早上试试大佬的模型,麻烦了
-
记得昨天的情况是修改完hina的config后bot.py也不能正常启动了 现在没办法给大佬看后台 早上起来看见骰子被238风控了 等上完课回来看看怎么处理
-
1.修复模糊匹配词库导出出错的问题。
2.修改wReply,匹配回复现在会快些。 -
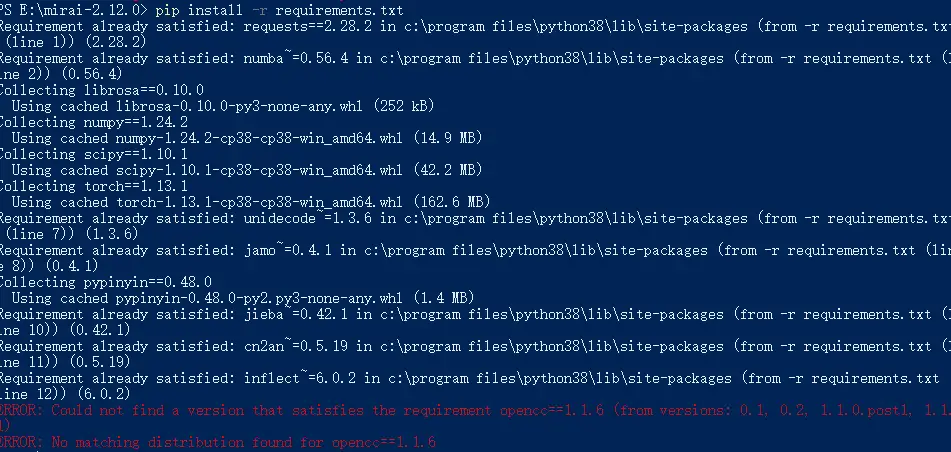 这是什么情况
这是什么情况 -
@六花123 换源/更新pip/修改requirements.txt中的OpenCC为OpenCC~=1.1.1/更换python版本为压缩包中的py3.9
-
2023-03-13 14:54:15| 中文语音生成-----> [ZH]早上好[ZH]
Traceback (most recent call last):
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python39\lib\site-packages\mirai\utils.py", line 20, in async_with_exception
return await async_(obj)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python39\lib\site-packages\mirai\utils.py", line 14, in async_
return (await obj) if inspect.isawaitable(obj) else obj
File "C:\Users\Administrator\Desktop\AI\voiceGenerateBeta_2\PythonPlugins\plugins\voicePart.py", line 101, in handle_group_message
voiceGenerate(tex, out, speakerId, modelSelect)
File "C:\Users\Administrator\Desktop\AI\voiceGenerateBeta_2\PythonPlugins\MoeGoe.py", line 138, in voiceGenerate
stn_tst = get_text(text, hps_ms, cleaned=cleaned)
File "C:\Users\Administrator\Desktop\AI\voiceGenerateBeta_2\PythonPlugins\MoeGoe.py", line 31, in get_text
text_norm = text_to_sequence(text, hps.symbols, hps.data.text_cleaners)
File "C:\Users\Administrator\Desktop\AI\voiceGenerateBeta_2\PythonPlugins\text_init_.py", line 17, in text_to_sequence
clean_text = clean_text(text, cleaner_names)
File "C:\Users\Administrator\Desktop\AI\voiceGenerateBeta_2\PythonPlugins\text_init.py", line 31, in clean_text
text = cleaner(text)
File "C:\Users\Administrator\Desktop\AI\voiceGenerateBeta_2\PythonPlugins\text\cleaners.py", line 36, in zh_ja_mixture_cleaners
from text.mandarin import chinese_to_romaji
File "C:\Users\Administrator\Desktop\AI\voiceGenerateBeta_2\PythonPlugins\text\mandarin.py", line 10, in <module>
jieba.set_dictionary(os.path.dirname(sys.argv[0])+'/jieba/dict.txt')
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python39\lib\site-packages\jieba_init.py", line 513, in set_dictionary
raise Exception("jieba: file does not exist: " + abs_path)
Exception: jieba: file does not exist: C:\jieba\dict.txt -
这个报错不知道该怎么办
-
@miyamax 不知道啥原因导致的,之前也有人反馈过,解决方法是把PythonPlugins\jieba\dict.txt复制到C:\jieba\dict.txt
C盘下没有对应文件夹的话新建一个。 -
@Anstiya 可以是可以了,但是只发送一秒的语音,也没声音
-
@miyamax 因为生成的语音没有转码,所以目前只有手机版qq可以听到
-
@Anstiya C:\Users\Administrator\AppData\Local\Programs\Python\Python39\lib\site-packages\fuzzywuzzy\fuzz.py:11: UserWarning: Using slow pure-python SequenceMatcher. Install python-Levenshtein to remove this warning
warnings.warn('Using slow pure-python SequenceMatcher. Install python-Levenshtein to remove this warning')
这个是每次启动时显示的,有影响吗,没有就不管了