NovelAi
最近novelai的模型被曝了出来,所以快自己搭建一个免费的色图生成器吧
在colab上运行
https://colab.research.google.com/drive/1gk-R0lx0T_Pk3kETvcMDs4Js8vxzSaKm?usp=sharing
首先打开colab的GPU支持
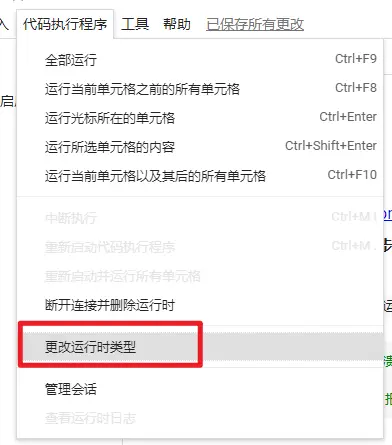
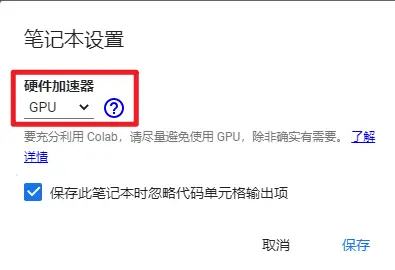
然后鼠标指到每个代码段前面,点击运行即可
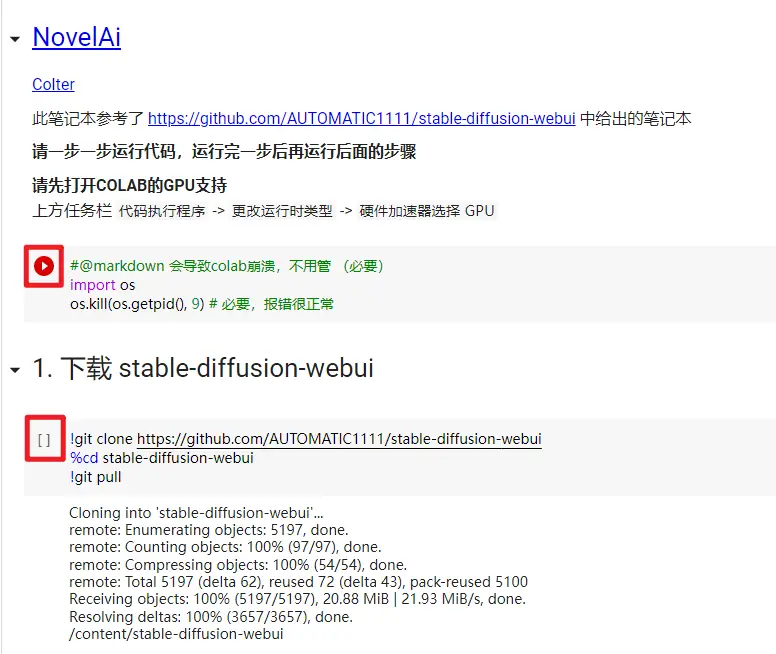
在本地运行
如果你实在搭建不起来,那么就去b站找一件启动包吧,或者用上面的在线运行
环境
请确保你的网络通常,以及防火墙
首先确保你有一张10系及以上的Nvidia显卡,如果你是AMD的显卡,可能需要在linux下进行操作
16G内存
需要磁盘空间 15G 左右(大概
16系显卡有点特殊,请注意下面教程中的说明
下面的教程使用的是windows
资源
模型资源
magnet:?xt=urn:btih:5bde442da86265b670a3e5ea3163afad2c6f8ecc
只需要下载一个模型即可
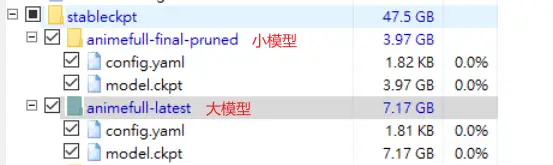
模型在 stableckpt 目录下
能用到的模型有两个:
animefull-final-pruned:4G小模型(如果你的显存小于等于4G, 下这个)
animefull-latest:7G大模型(如果显存大于等于6G, 用这个, 顺便把小模型的config.yaml也下载下来,有用)
模型文件夹里有两个文件(都要下载):
config.yaml:模型的配置文件
model.ckpt:模型
大模型的效果比较好
CUDA
https://developer.nvidia.com/cuda-downloads
下载后安装
Python 3.10
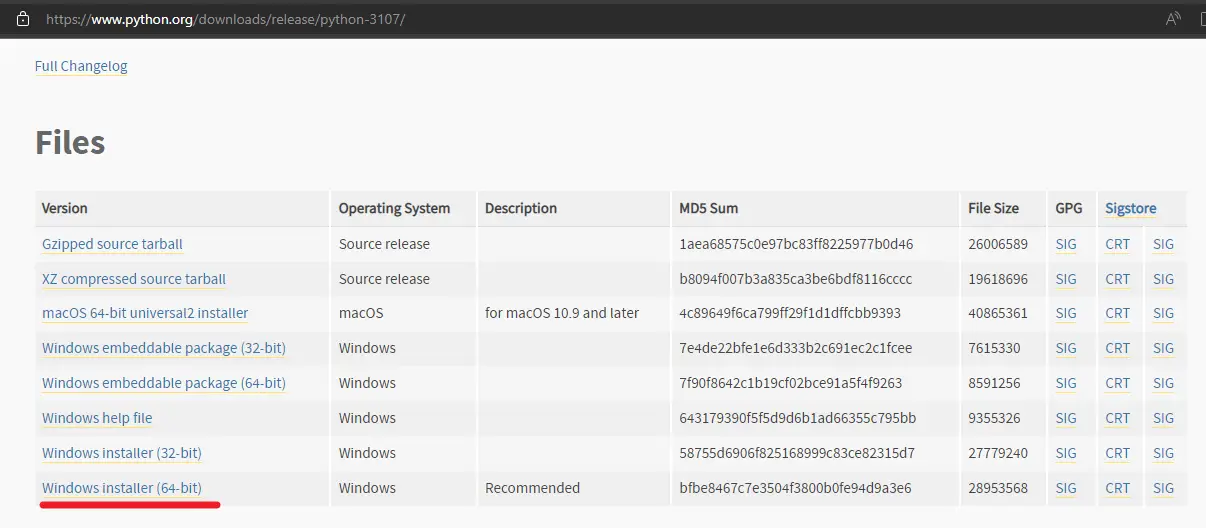
https://www.python.org/downloads/release/python-3107
翻到页面最下面的文件列表,一般用最后一个
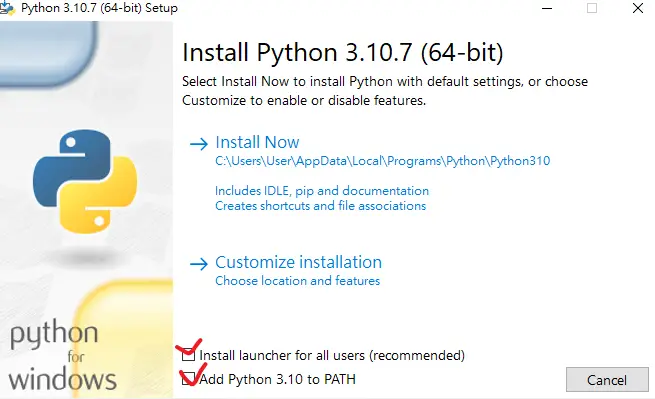
安装时起始页面有两个勾都勾上
Git
webui
https://github.com/AUTOMATIC1111/stable-diffusion-webui
使用 git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git 下载,之后每次运行前都可以拉去一下更新 git pull
如果你的git报错,请确保你安装了git并设置了账号信息(git如何设置账号信息请自行搜索)然后再检查你的网络是否通畅(无法正常使用git的话就开个加速器或者优化git的软件,如 dev-sidecar等,或者自行搜索git加速的方法),如果还不行的话就关闭防火墙试试。
准备
上述资源准备好后
1. 放置模型文件 model.ckpt
来到 stable-diffusion-webui 项目目录中(后面的操作如果没有特殊说明都在这个项目中完成)
把模型文件 model.ckpt 放到 models\Stable-diffusion 目录中 (看清楚是models目录, 不是modules目录)
2. 初始化运行
!!! 如果你的显卡是16系显卡,请进行下面的操作 !!!
在项目根目录找到
webui-user.bat并编辑
在set COMMANDLINE_ARGS=后面加上--precision full --no-half参数
完整webui-user.bat如下@echo off set PYTHON= set GIT= set VENV_DIR= set COMMANDLINE_ARGS=--precision full --no-half call webui.bat
在项目根目录找到 webui-user.bat 运行 (! 不要使用管理员运行 !)
运行会安装必要的依赖,但没有进度条
如果你的网络顺畅那么下面那些问题应该都不会有
如果太长时间未相应或你想看进度可以手动安装依赖(但必须先运行一遍 webui-user.bat,卡住后 ctrl+c 退出)
手动安装依赖:
如果手动安装失败,那就老老实实用webui-user.bat吧
请确保你项目根目录下有venv文件夹, 没有就去执行一下webui-user.bat(不用执行完,等他安装卡住时退出即可
在根目录下运行cmd
执行命令./venv/Scripts/pip.exe install -r ./requirements.txt
一定要用项目环境中的pip
安装完成后再次运行webui-user.bat
python依赖安装完成后如果出现 git clone xxx 报错,可手动安装github依赖库
手动安装github依赖库
主要是下面这个github库比较大
https://github.com/CompVis/taming-transformers在项目根目录找到
repositories文件夹,没有就自己建一个
把上面那个库放到这里,git clone
安装完成后再次运行webui-user.bat
python依赖与github库依赖都下载完后还会下载1个多G的数据
如果一切正常最后会看到一个URL: http://127.0.0.1:7860
先不要着急去体验,现在模型还发挥不出他应有的实力,先 ctrl+c中止运行,然后继续下面的步骤
3. 放置模型配置文件 config.yaml
把模型对应的 config.yaml 放置到 repositories\stable-diffusion\configs\stable-diffusion 目录下
替换原来的 v1-inference.yaml (把你的配置改名成这个
如果你没有 repositories 这个目录,那么就说明你上面项目初始化没做完
!!! 注意 !!!
如果你是小模型就直接替换
如果你用的大模型且你的显存小于等于6G,请使用小模型的config (否则可能会爆显存
如果你的显存大于等于8G可以尝试使用大模型的config (如果不行的话就换小模型的config
再去根目录运行 webui-user.bat 启动,然后就可以愉快的玩耍了
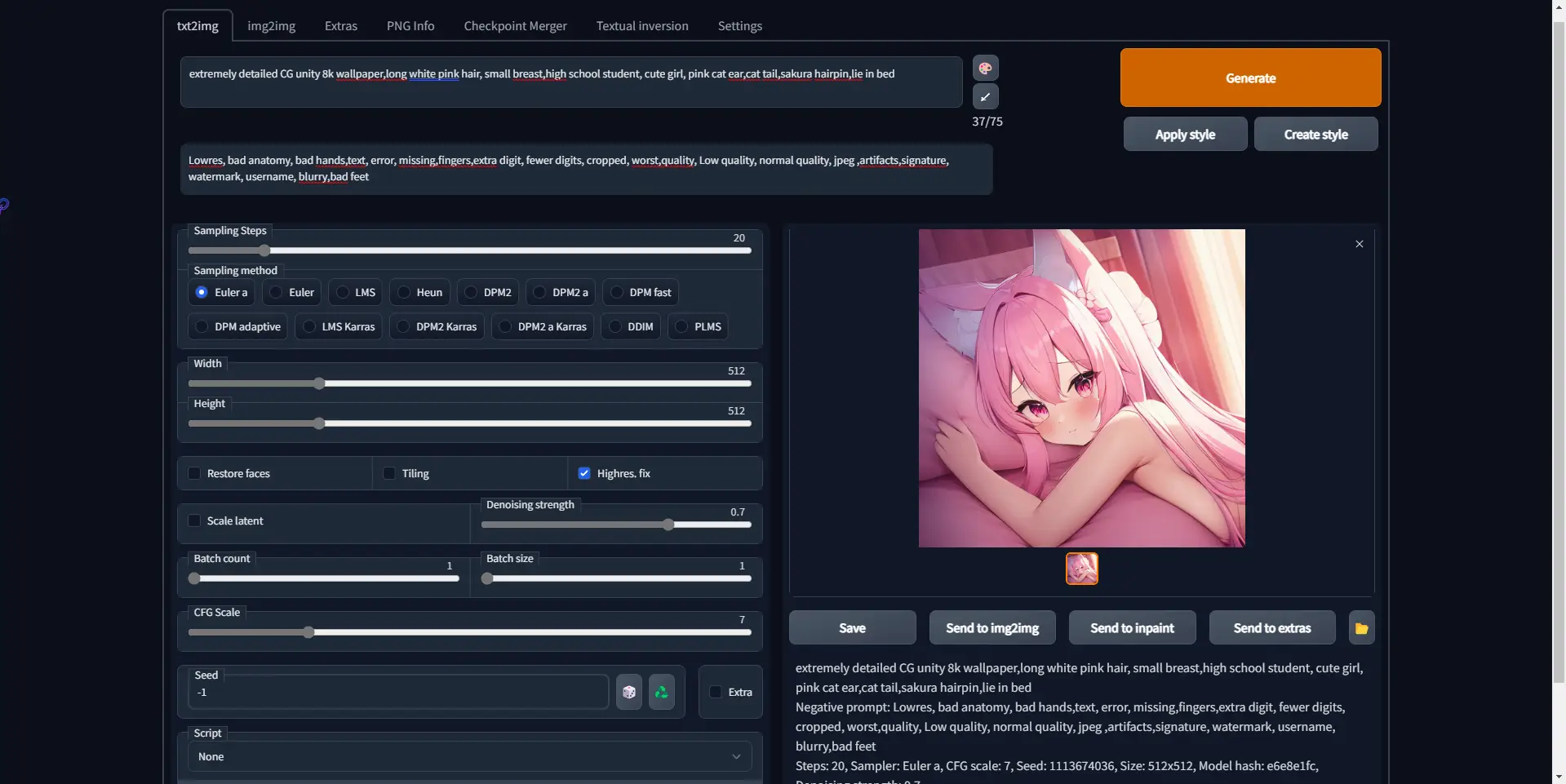
4. 使用
如果你想要在其他设备上使用,可在 webui-user.bat 里的 COMMANDLINE_ARGS= 后面加上 --listen 参数
页面中的参数大部分默认就行,你可以调整一下输出图片高度(但要量力而行,否则可能爆显存
Prompt 输入框就是你输入tag的地方,每个tag间用逗号隔开。可以加上这几个tag,效果更好些 masterpiece, best quality,highly detailed,
更多tag可去danbooru上查看
Negative prompt 建议使用下面这组tag,可以优化输出品质
lowres, bad anatomy, bad hands,text, error, missing,fingers,extra digit, fewer digits, cropped, worst,quality, Low quality, normal quality, jpeg ,artifacts,signature, watermark, username, blurry,bad feet
Sampling Steps 建议 20-40 即可
Width ,Height 输出图片宽高(量力而行)
Batch count 批量输出数量
CFG Scale ai的创作度, 7-11
Seed 种子,可以用于生成根之前类似的图片(如果你生成一张还不错的图片,但细节还不够好,可以用他的种子继续生成类似的图片)
seed在生成的图片下边那一串英文的最后一行中间
生成的图片默认保存在项目根目录下的 outputs 目录中,不用点网页上那个保存
设置里最下边有个 Stop At last layers of CLIP model 滑条可以调到 2
如果想了解每个参数的具体含义,可看这个视频 https://www.bilibili.com/video/BV1V8411s76T
或者项目wiki https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki
其他
此教程中的很多内容来自网络以及群友(感谢